AWS Bedrock Tutorial - 음성파일로부터 자막과 이미지 생성하기(2)

이어서
음성파일을 S3 버킷에 업로드한 지난 게시글에 이어 음성 파일이 업로드 되는 순간 자막을 생성하고, 자막과 연관된 이미지를 생성하는 과정이 자동화 될 수 있도록 필요한 과정을 마저 진행한다.
0. 주의점
- 모든 서비스의 리전은 전부 같은 리전이어야 한다. 이 글에선 미국 동부(us-east-1)으로 진행한다.
- S3 버킷에 파일 생성을 트리거로 입력 파일을 받아 출력 파일을 생성하고, 그 출력 파일을 같은 버킷에 넣으면 안된다!!! 입력파일생성 - 트리거 - 출력파일생성(=입력파일생성) - 트리거 - 출력파일생성(=입력파일생성) - … 의 무한루프에 빠져 무한히 파일이 생성되며 요금 폭탄이 나올 수 있다. 따라서 반드시 입력파일이 생성되는 버킷과 출력파일이 생성되는 버킷은 구분해주어야 한다.
1. S3 버킷 생성
지난 게시글을 참고해 자막 파일을 업로드할 버킷 1개와 이미지 파일을 업로드할 버킷 1개를 각각 생성한다.
버킷 이름은 전 세계에서 중복되지 않는 이름이어야 하며, 본인이 구분하기 좋은 이름으로 설정하면 된다.
여기선 my-toy-bucket-upload-transcription-jay, my-toy-bucket-upload-image-jay로 각각 생성하고 진행한다.
2. Transcribe를 실행하는 Lambda 함수 생성

Lambda 서비스로 이동해 ‘함수 생성’을 누른다.
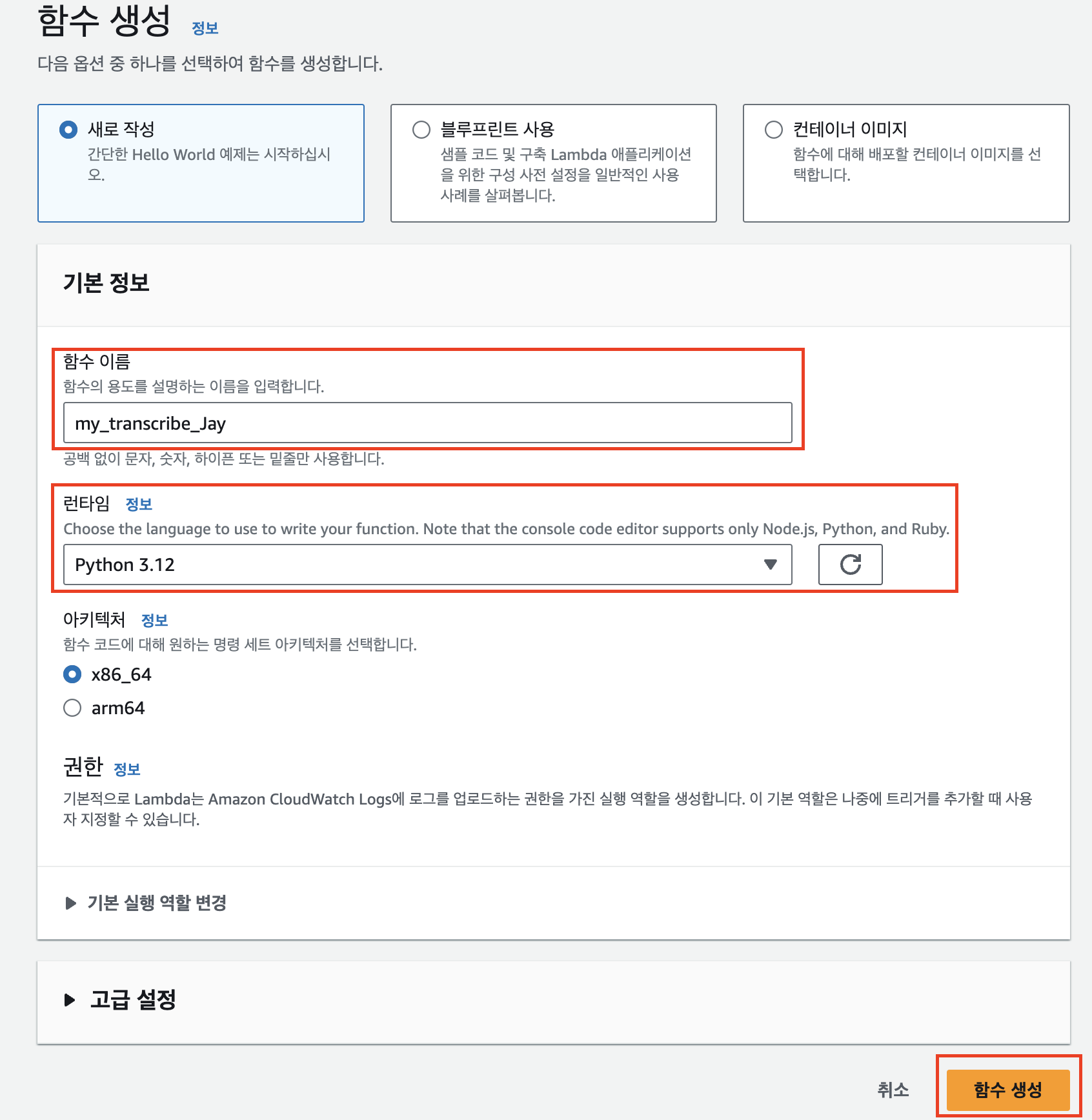
함수 이름을 입력하고, 런타임 언어로 파이썬을 선택한다. ‘함수 생성’을 누르면 기본 생성 역할과 함께 Lambda 함수가 생성된다.
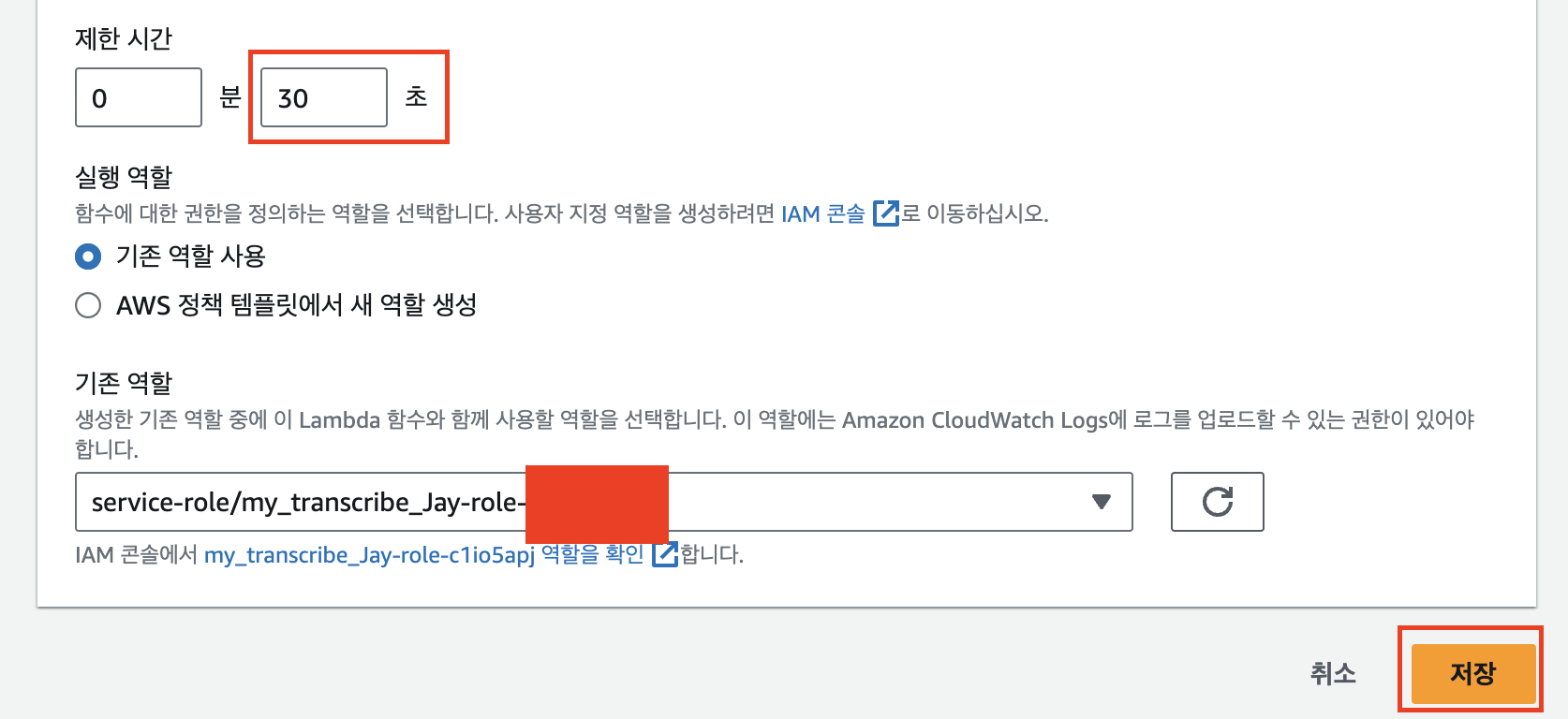
구성 - 일반 구성 - ‘편집’을 선택한다.
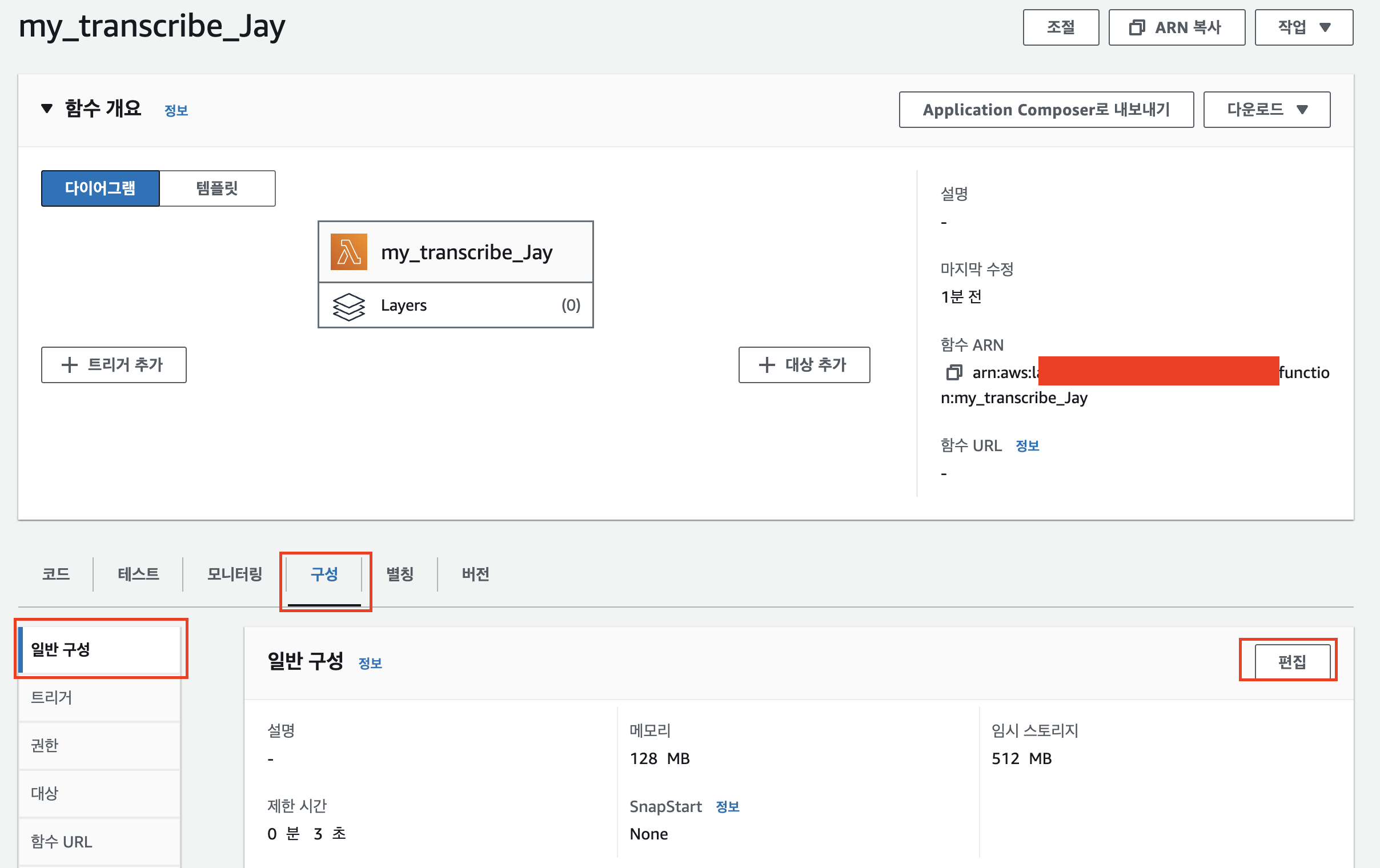
제한시간을 30초로 변경한다. Transcribe 모델 실행시간이 수십초 걸릴 수 있기 때문에 넉넉히 변경한다. ‘저장’을 누른다.
from botocore.exceptions import ClientError
from datetime import date, datetime
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel("INFO")
def json_serial(obj):
"""JSON serializer for objects not serializable by default json code"""
if isinstance(obj, (datetime, date)):
return obj.isoformat()
raise TypeError ("Type %s not serializable" % type(obj))
def lambda_handler(event, context):
# TODO implement
bucket_name = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
transcribe_client = boto3.client("transcribe")
job_name = 'my_transciption_job_{}_{}'.format(datetime.now().strftime('%Y%m%d_%H%M%S'), key)
try:
job_args = {
"TranscriptionJobName": job_name,
"Media": {"MediaFileUri": 's3://{}/{}'.format(bucket_name, key)},
"MediaFormat": 'mp3',
"LanguageCode": 'en-US',
##########################################
"OutputBucketName": Bucket-name-to-upload,
##########################################
"OutputKey": 'my_transcription_{}.json'.format(key.split('.')[0].split('_')[-1]),
"Settings":{
'ShowSpeakerLabels': True,
'MaxSpeakerLabels': 2
}
}
response = transcribe_client.start_transcription_job(**job_args)
response = json.dumps(response, default=json_serial)
logger.info("Started transcription job %s.", job_name)
except ClientError:
logger.exception("Couldn't start transcription job %s.", job_name)
raise
else:
return response
logger.info("job done")
logger.info(json.loads(response))
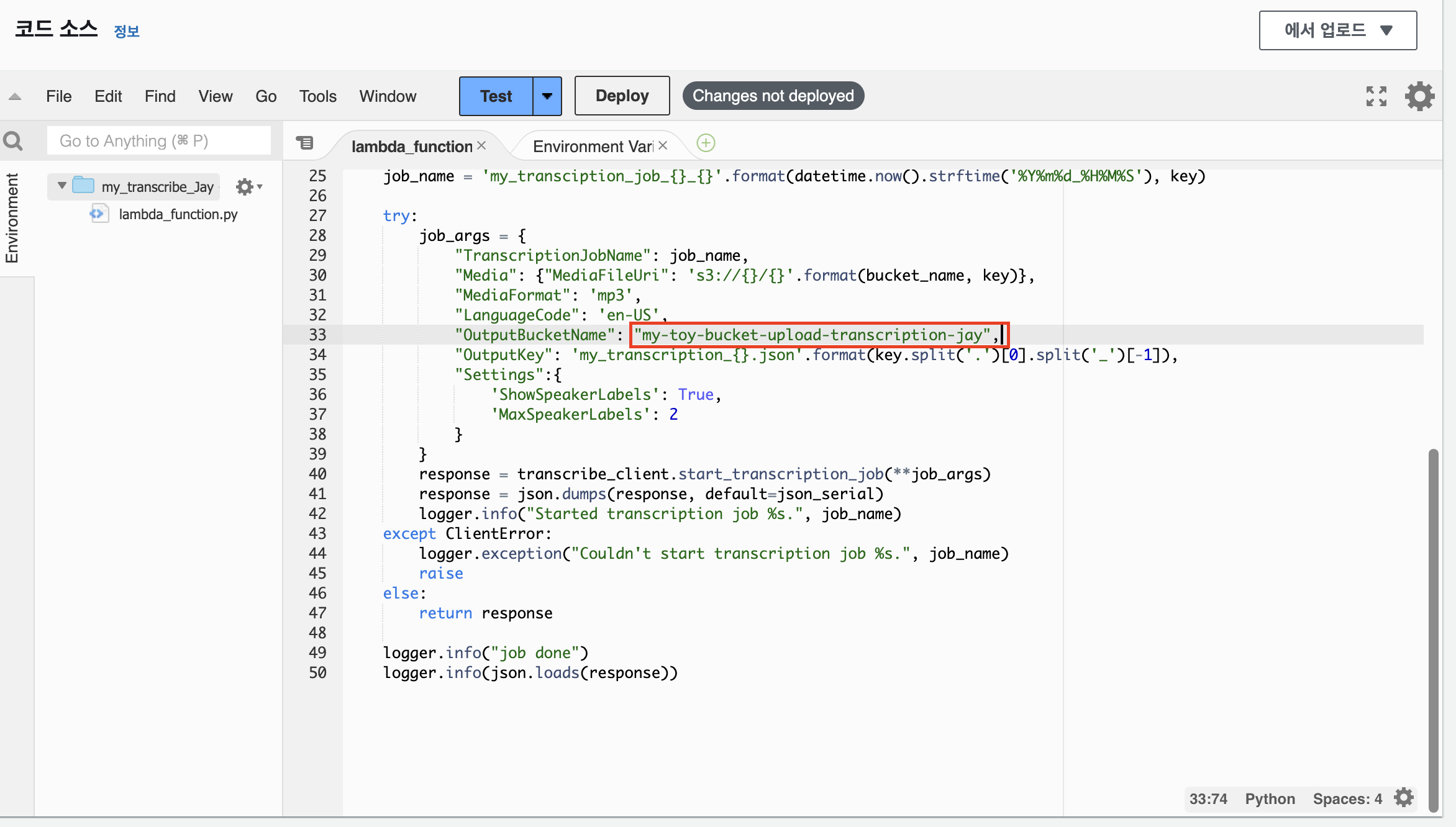
코드 창에 위의 함수를 붙여넣는다. Bucket-name-to-upload에는 앞에서 생성한 자막 파일 업로드용 버킷의 이름을 넣는다.
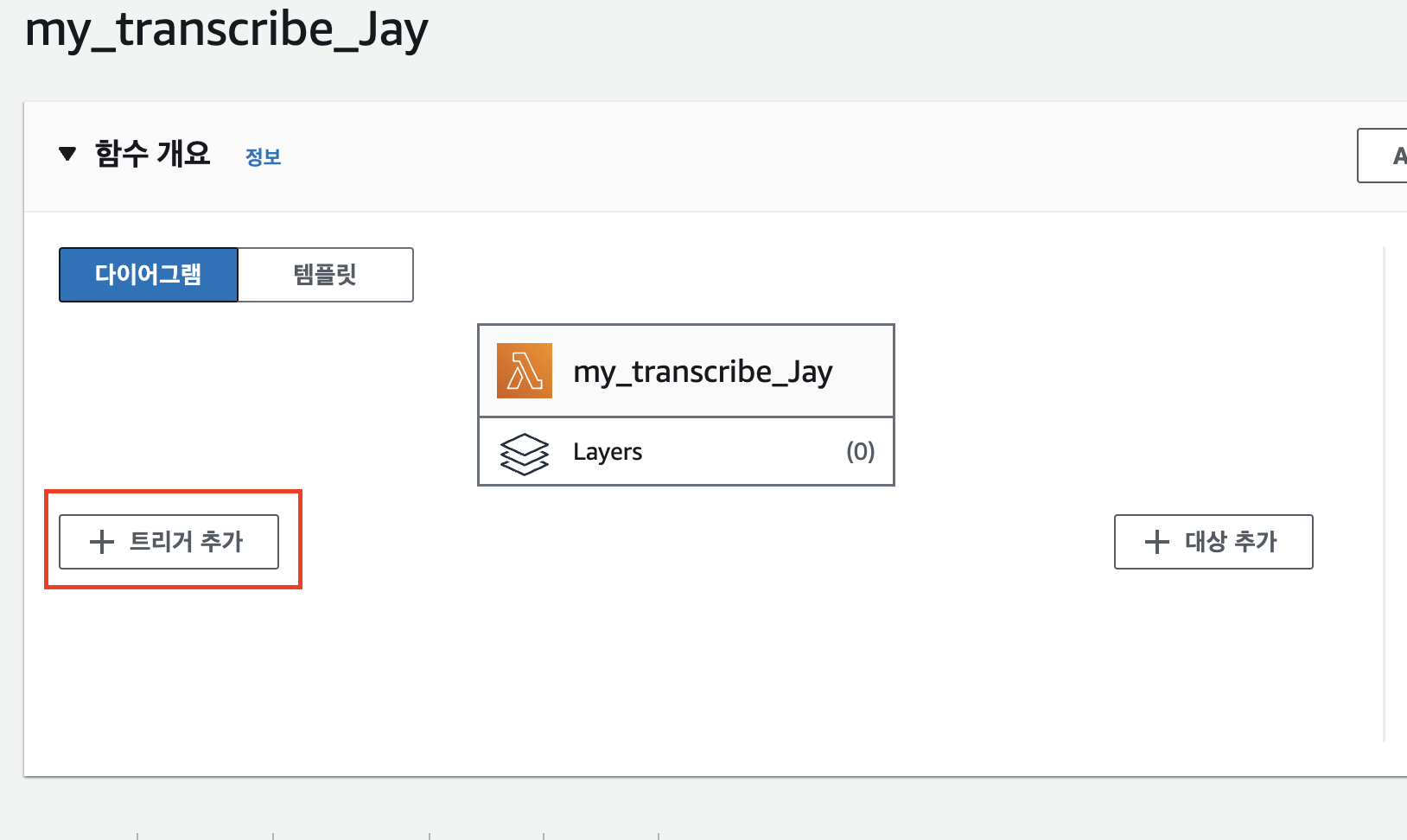
위로 가 ‘트리거 추가’를 누른다.
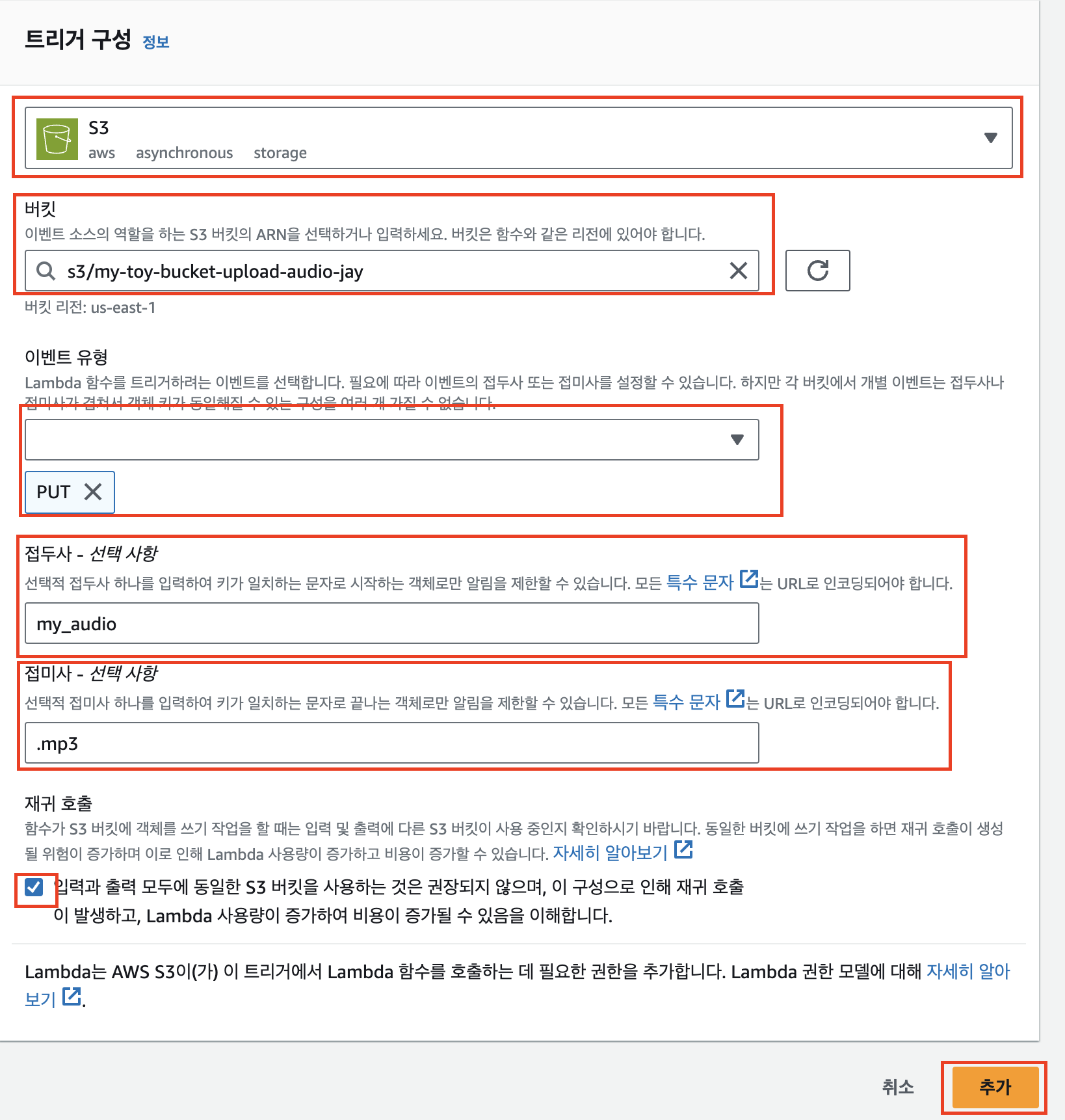
소스 선택에서 ‘S3’를 선택한다.
이후 버킷 선택에서 음성 파일이 업로드된 버킷을 선택하고, 이벤트 유형에는 다른 유형은 다 삭제하고 PUT만 추가한다. 트리거가 발생할 파일명의 조건으로는 접두사로 my_audio, 접미사로 .mp3를 입력해 다른 유형의 파일이 생성되었을 때 필요 없는 함수 호출이 없도록 방지한다. 마지막으로 재귀 호출에 체크하고 ‘추가’를 누른다.

구성 - 권한 - 역할 이름 링크를 클릭해 IAM 서비스로 이동한다.
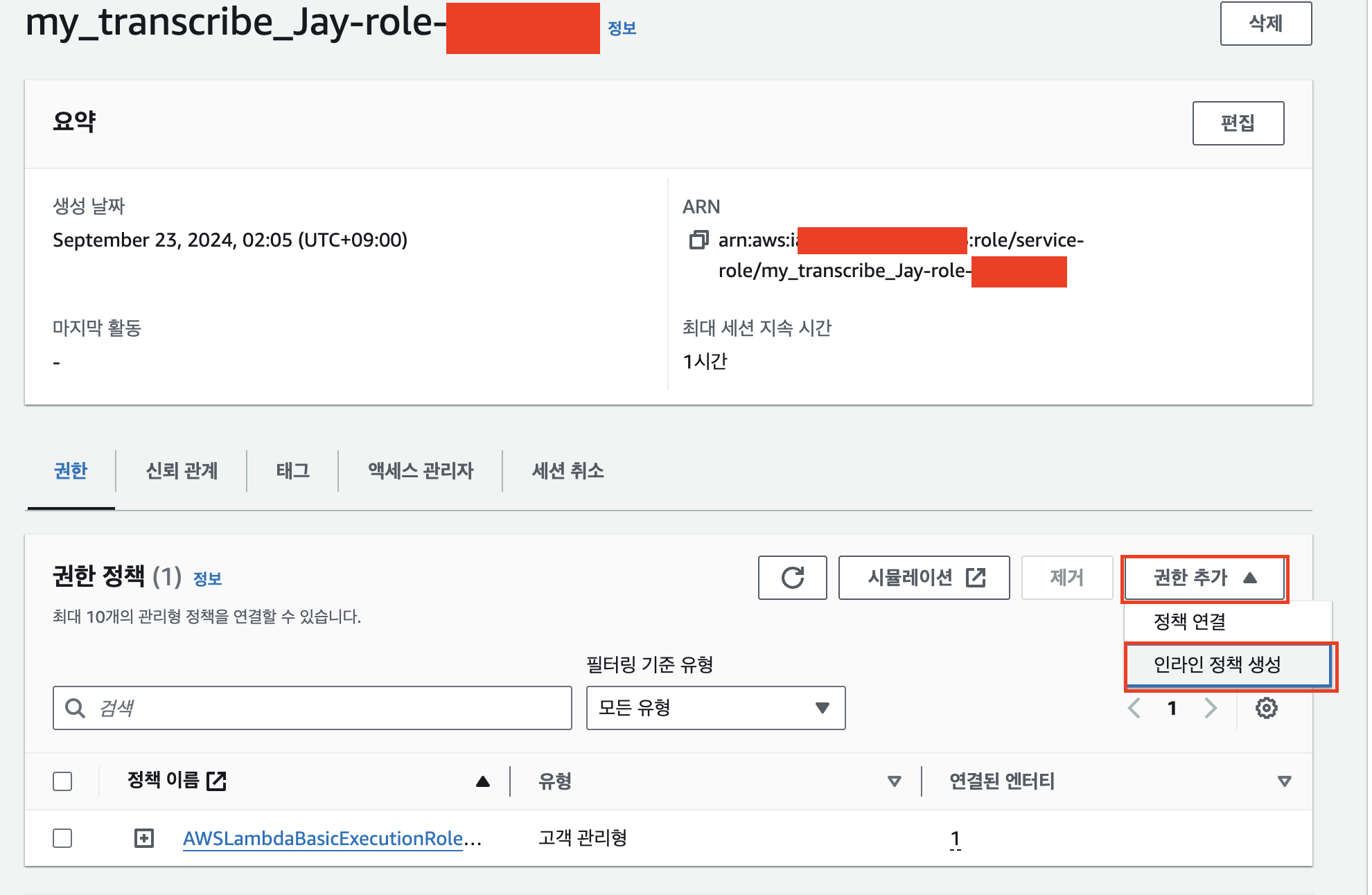
권한 추가의 ‘인라인 정책 생성’을 클릭한다.
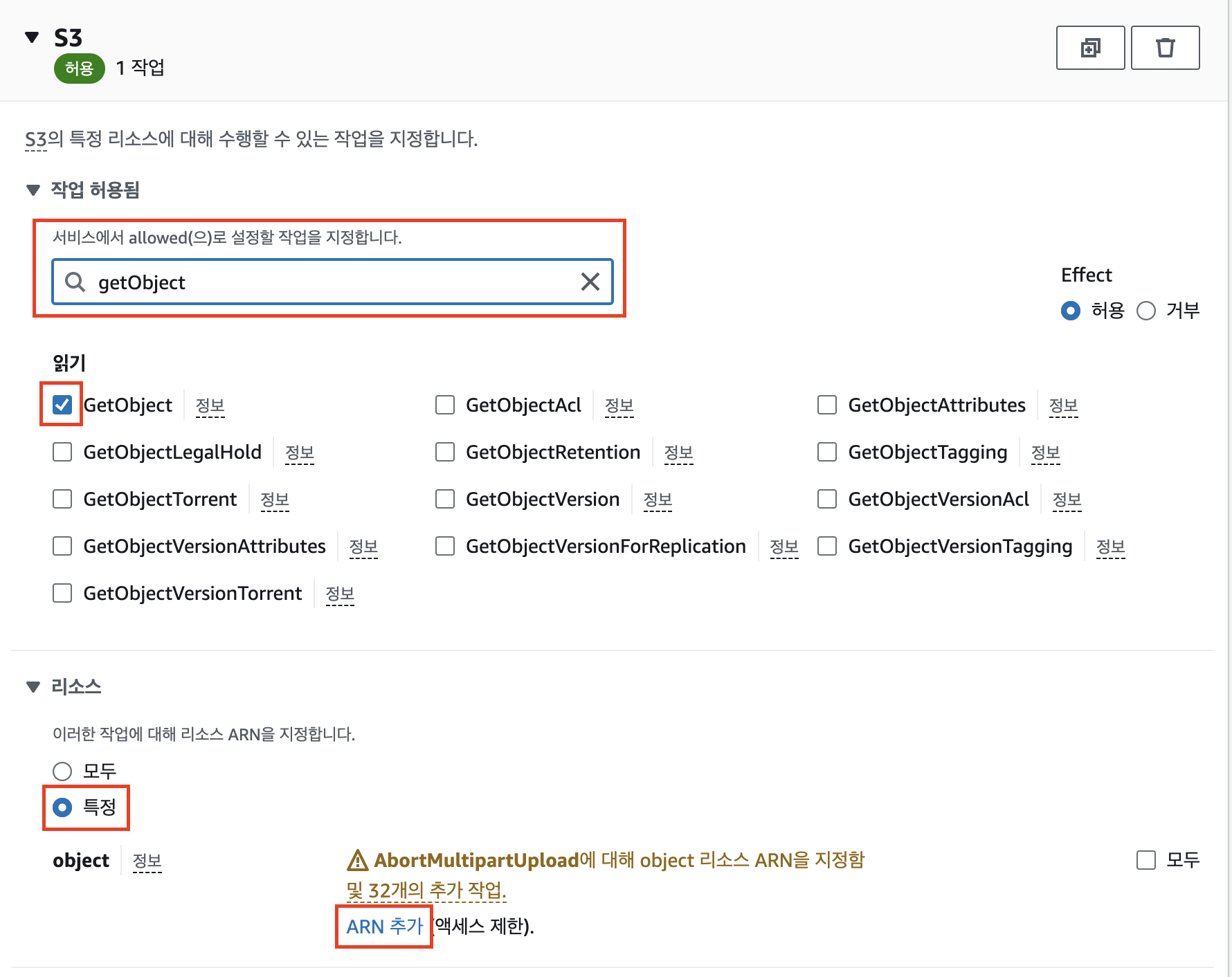
검색창에 getObject를 입력 후 체크박스 선택. 리소스 항목에선 특정을 선택 후 ‘ARN 추가’를 누른다.
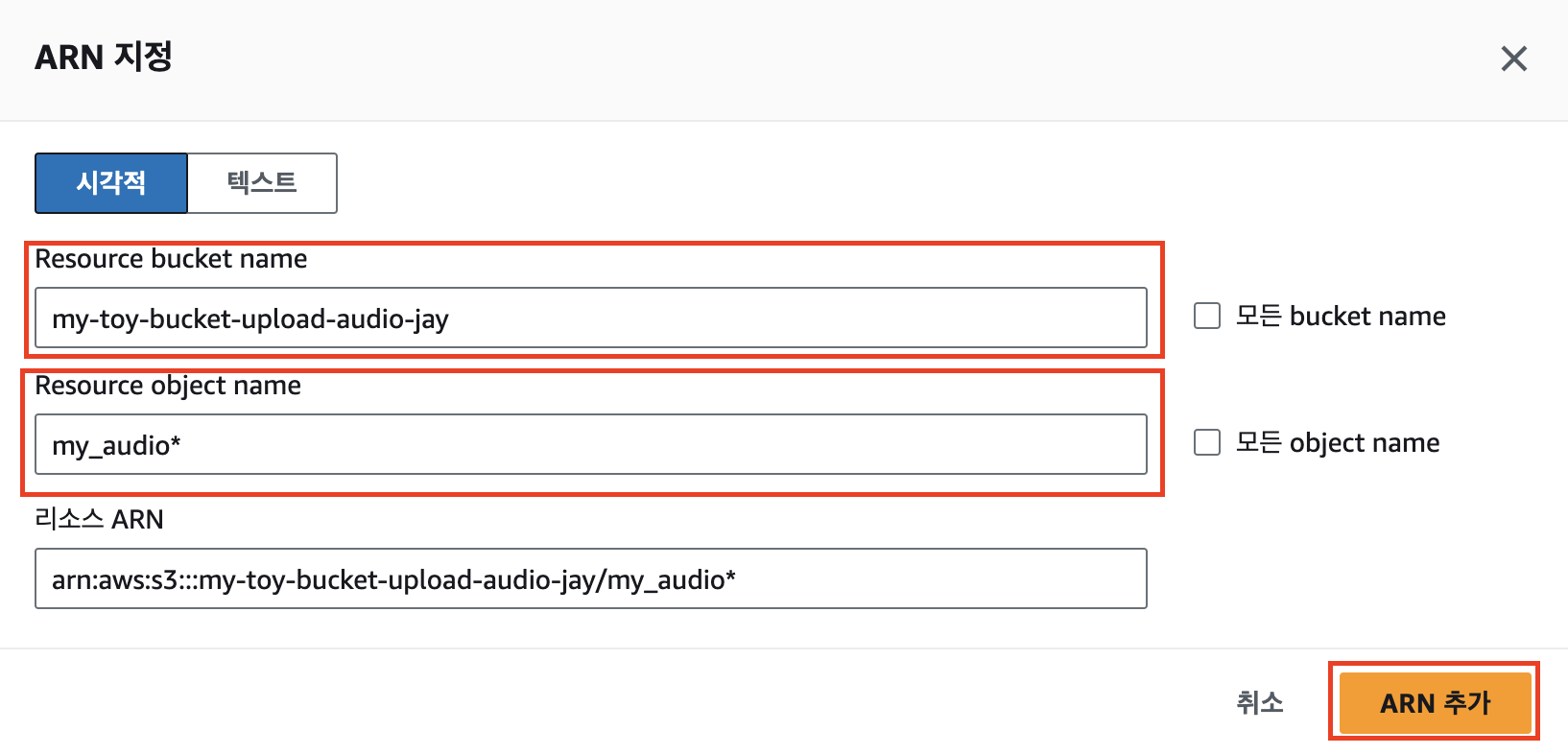
음성 파일이 업로드 된 버킷명을 bucket name에 입력하고, 음성 파일명의 접두사를 object name에 입력 후 ‘ARN 추가’를 누른다.

하단의 ‘권한 더 추가’를 눌러 PutObject 권한도 추가해줄 것이다.
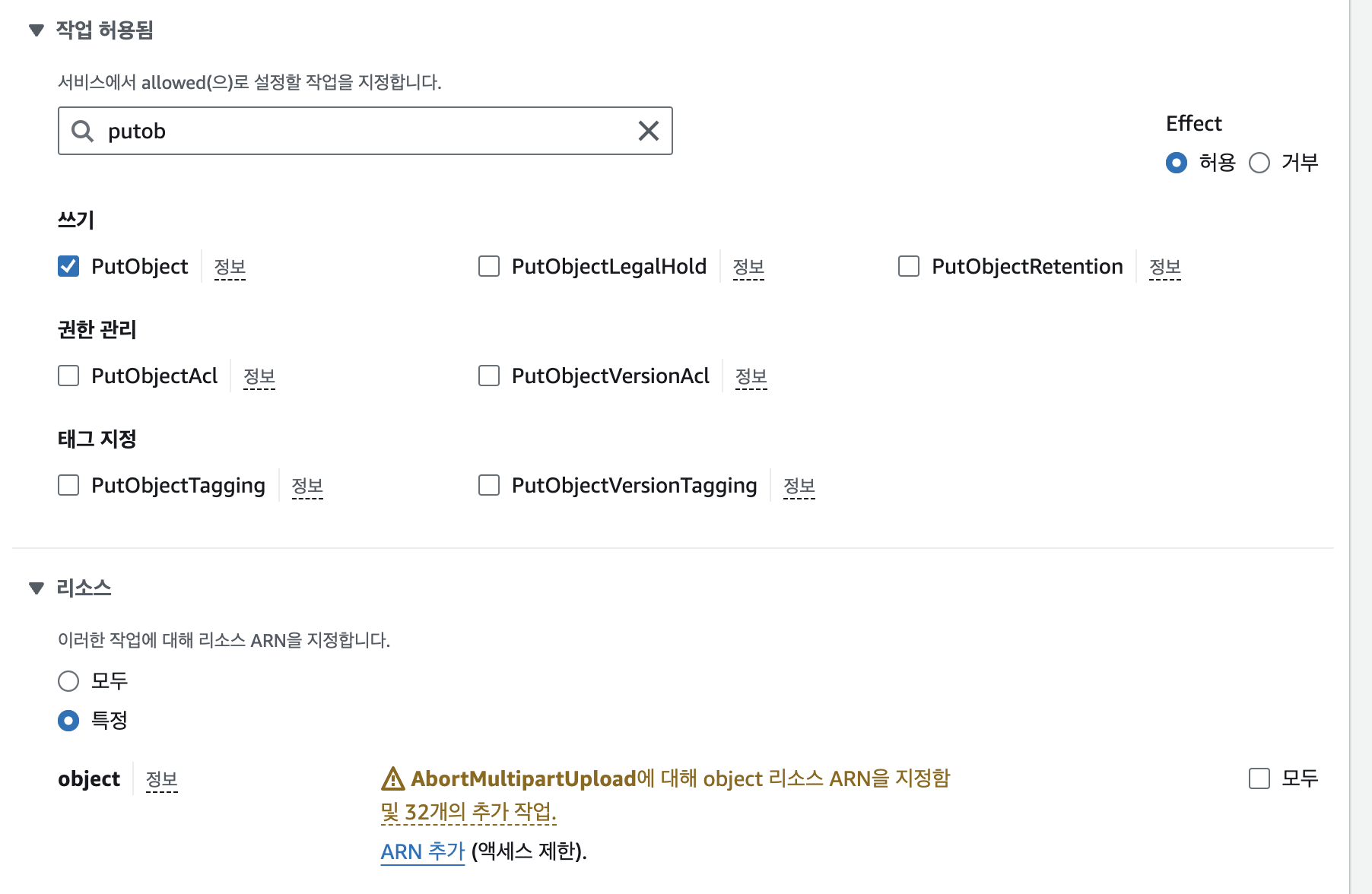
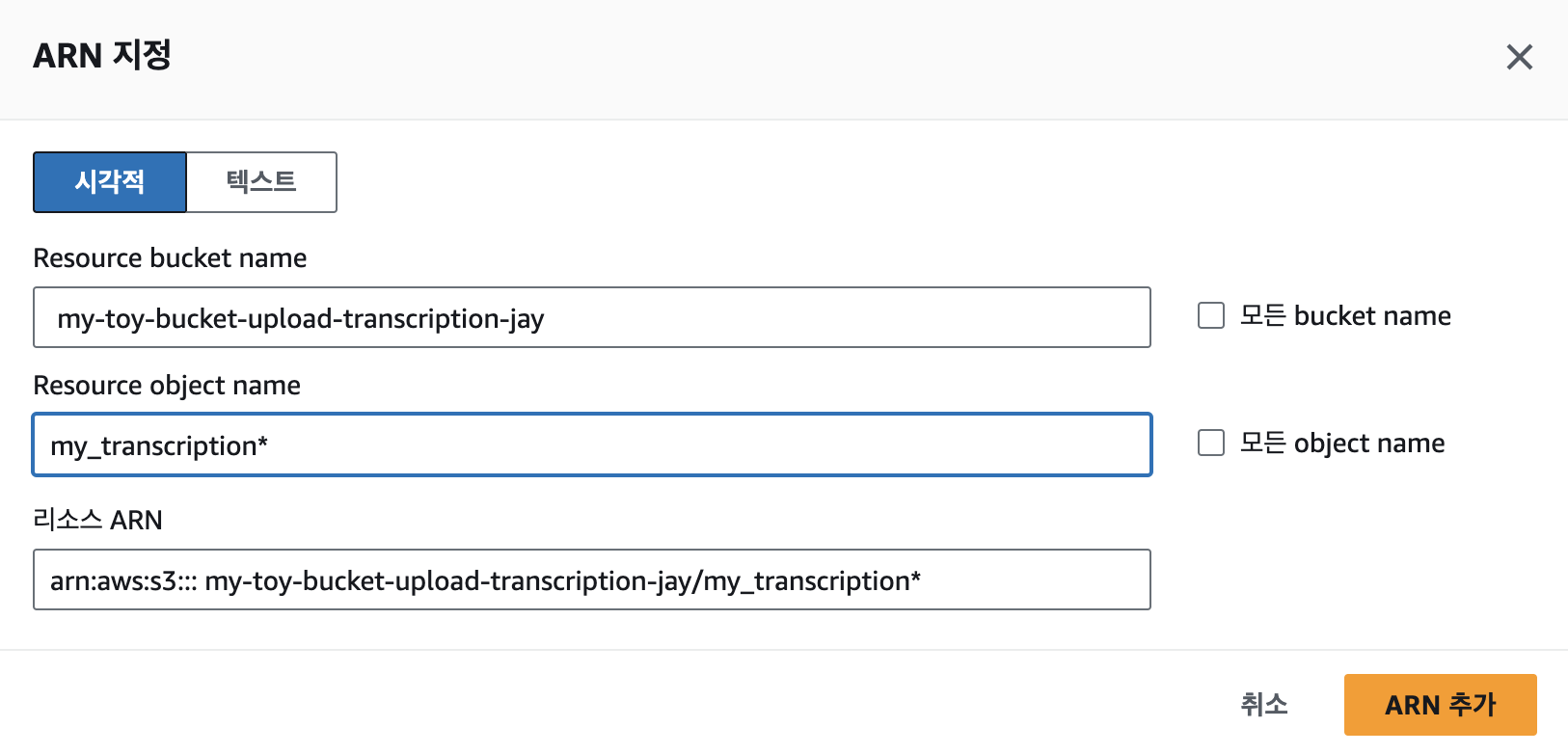
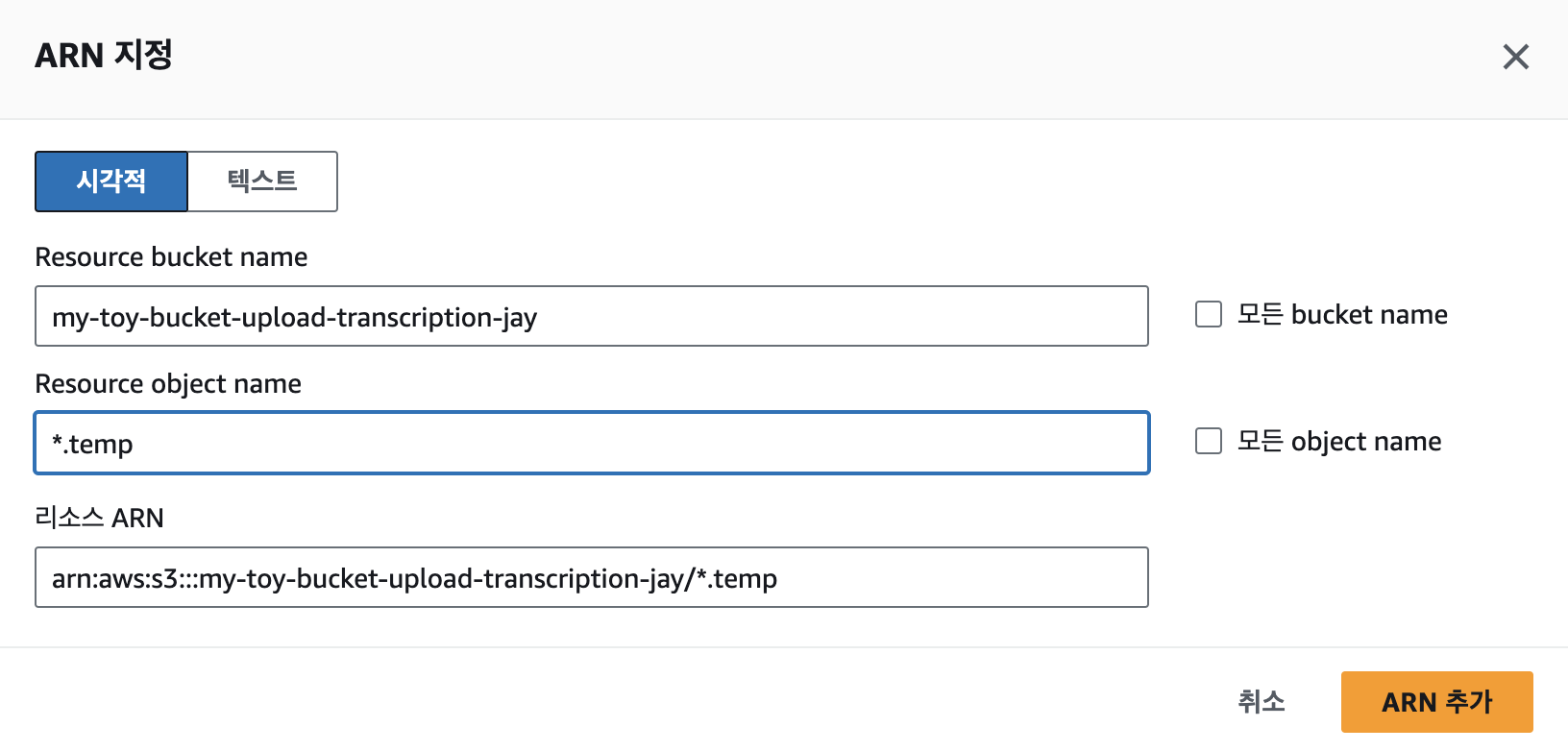
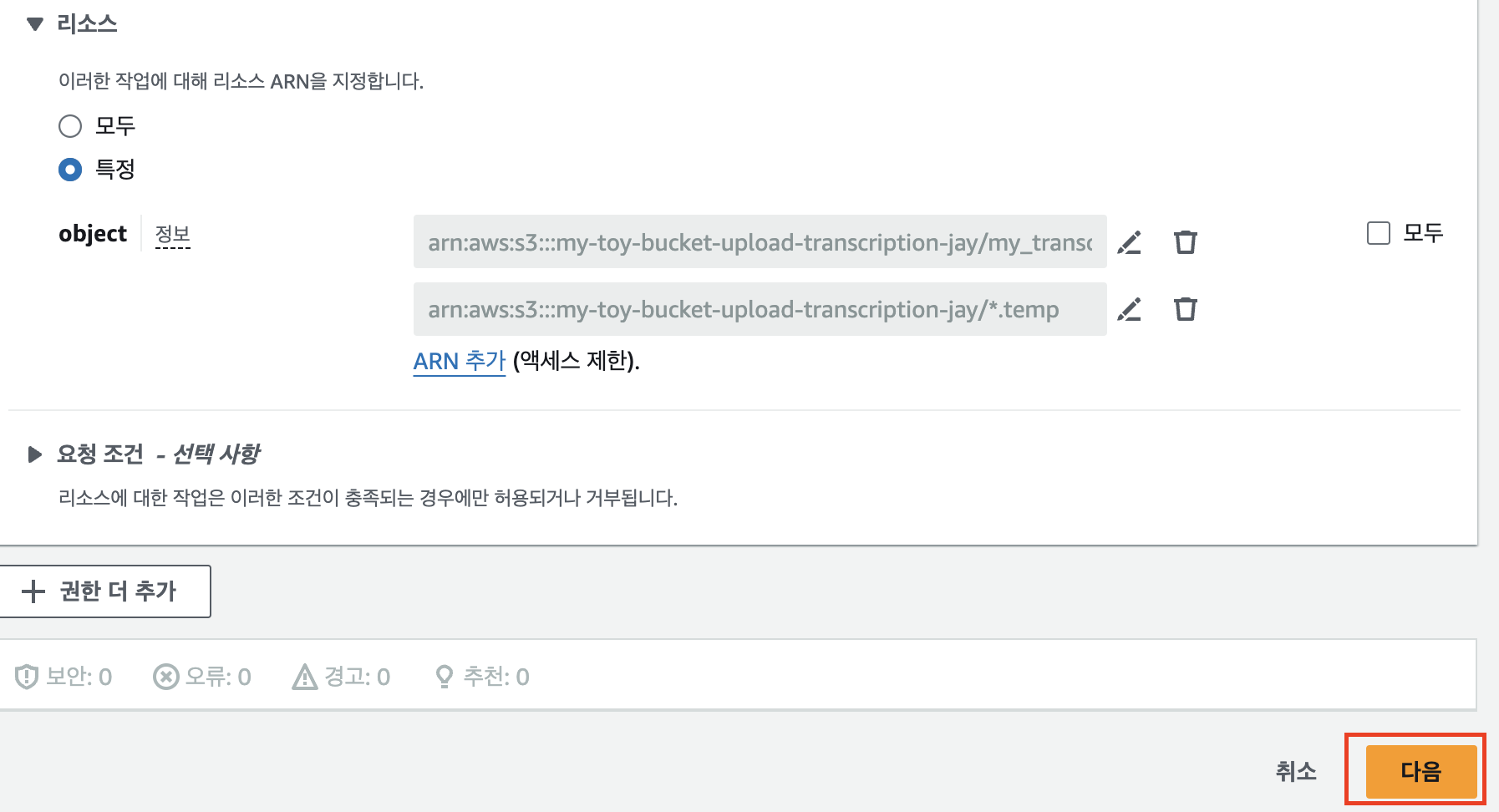
위에서 GetObject와 동일하게 PutObject도 추가해주고, ARN은 이번엔 자막파일을 업로드 할 버킷의 이름과 접두사를 입력한다. 또한 자막파일 생성시 temp파일도 생성되므로 ARN을 하나 더 추가한다. 다 됐으면 다음을 누른다.
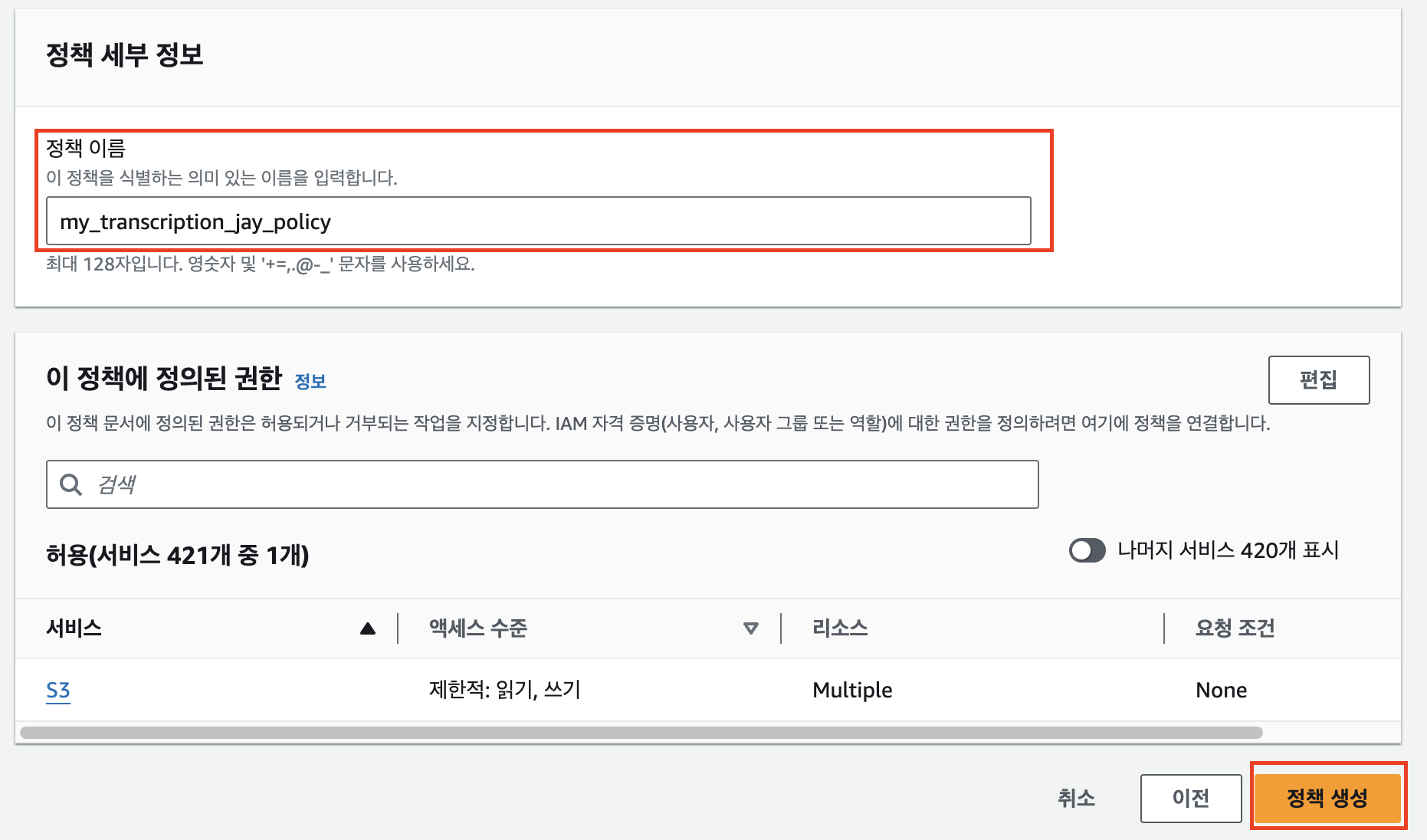
적당한 정책 이름 입력 후 ‘정책 생성’을 클릭한다.
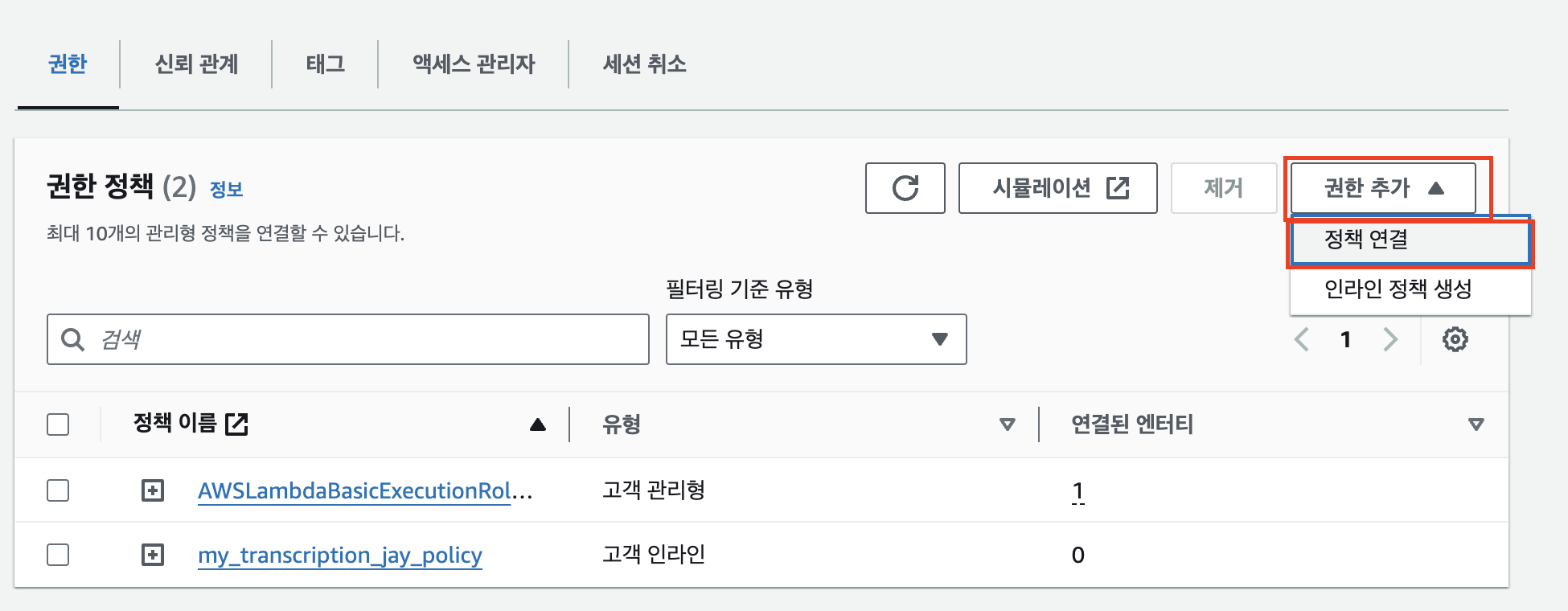
정책 하나를 더 연결해야 한다. 이번엔 기본적으로 있는 정책을 가져온다. 권한 추가의 ‘정책 연결’을 누른다.
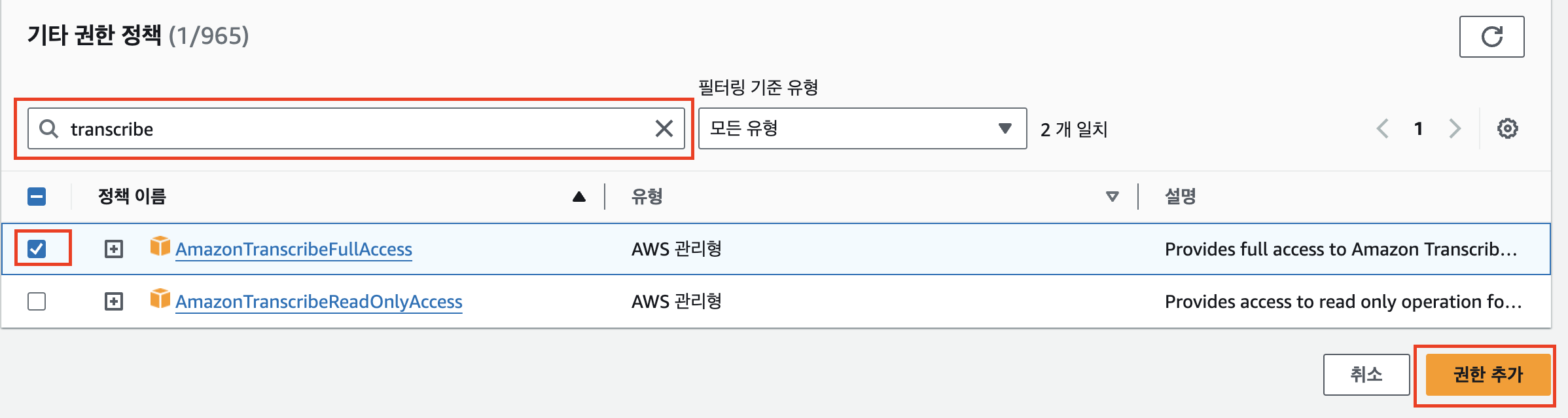
transcribe를 검색해 AmazonTranscribeFullAccess 정책의 체크박스를 클릭한다. 사실 이 정책도 세부적으로 선택할 수 있겠지만 잘 모르는 부분이기도 하고 토이프로젝트니 FullAccess 정책으로 선택한다.
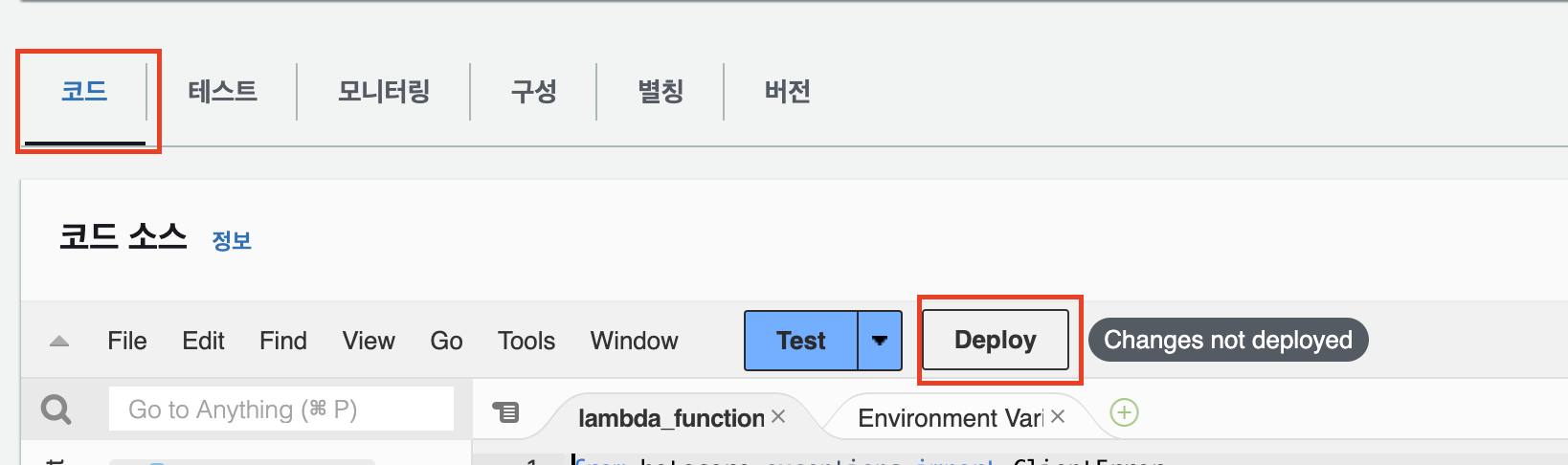
다시 Lambda 함수로 돌아와 Deploy로 함수를 배포한다.

Test 버튼을 눌러 새 테스트를 생성 후 한번 실행시켜 CloudWatch에 로그가 기록되도록 한다. 테스트는 실패해도 상관없으니 아무렇게나 생성하고 실행하면 된다.
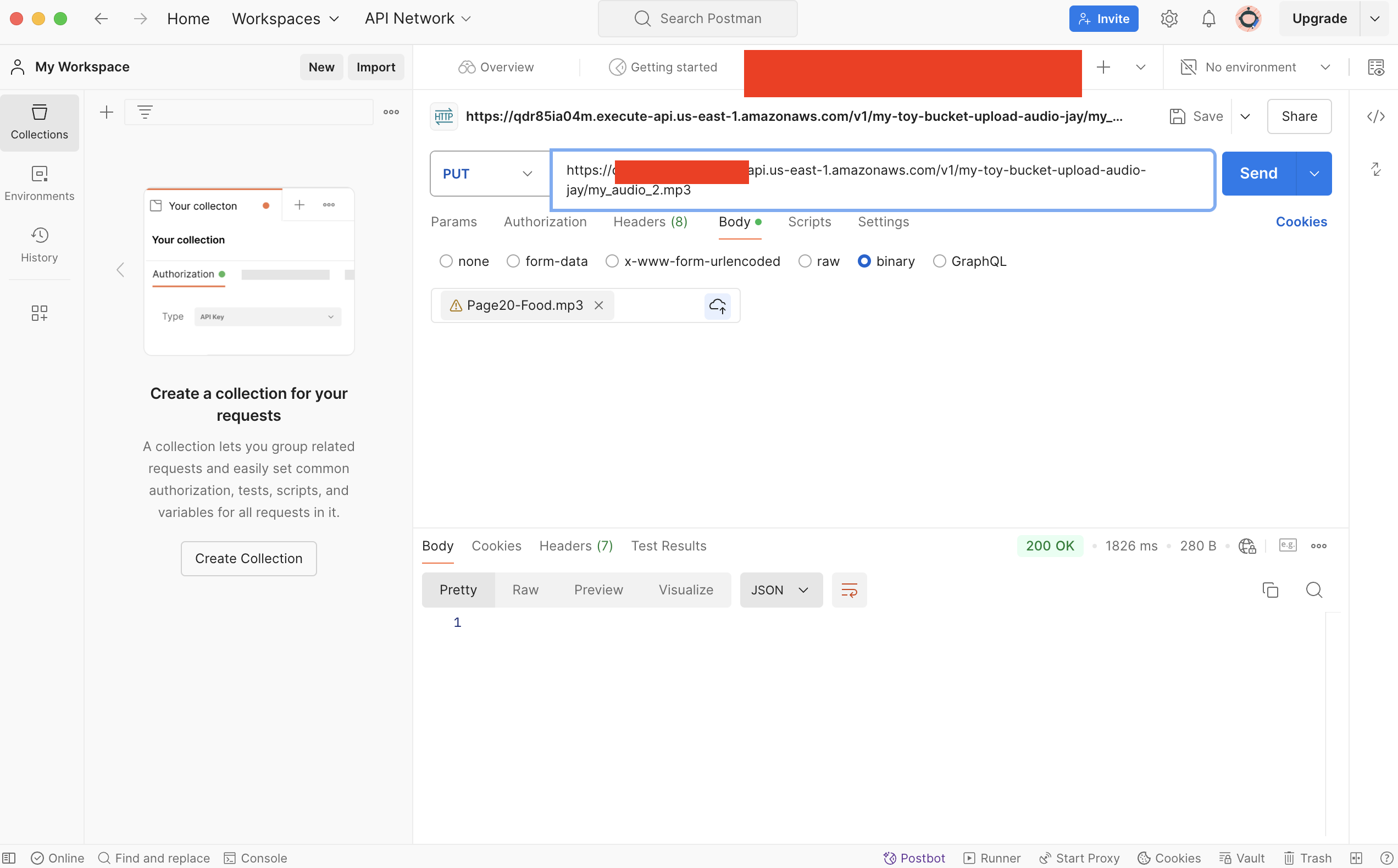
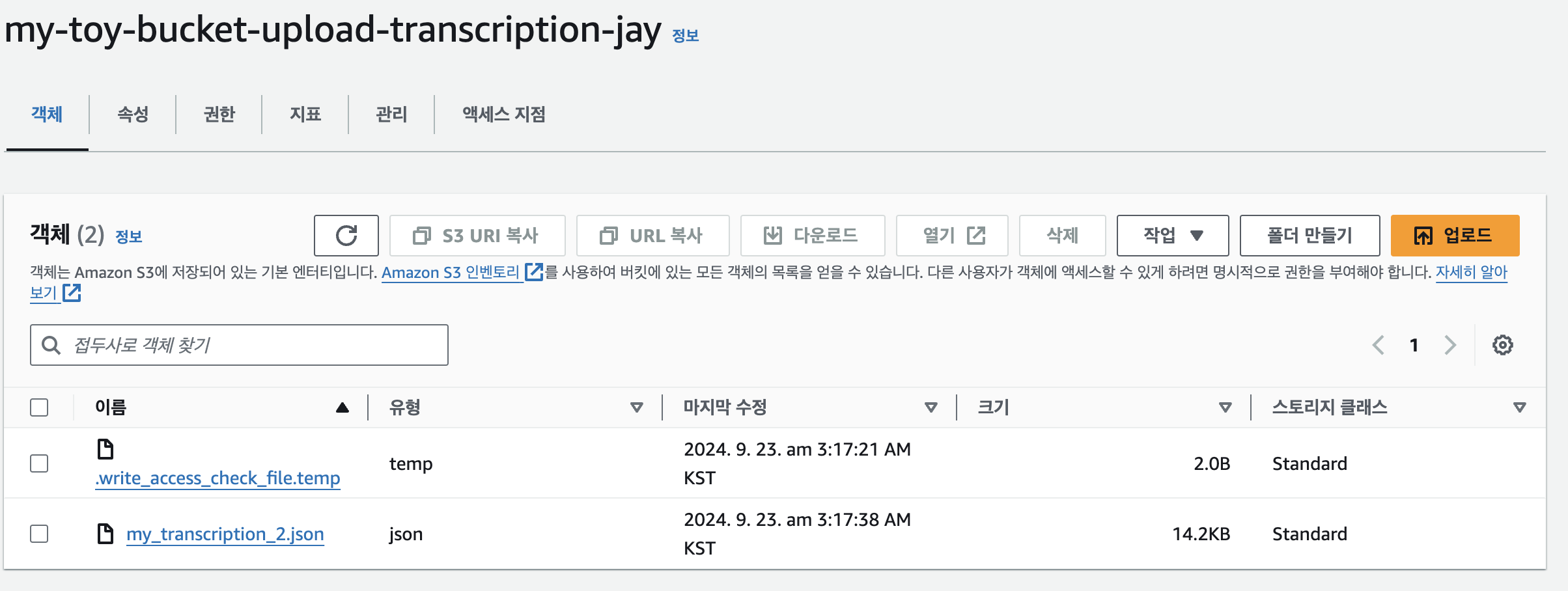
Postman에서 테스트로 음성 파일 업로드 시, 자막파일까지 순차적으로 생성된다면 성공이다.
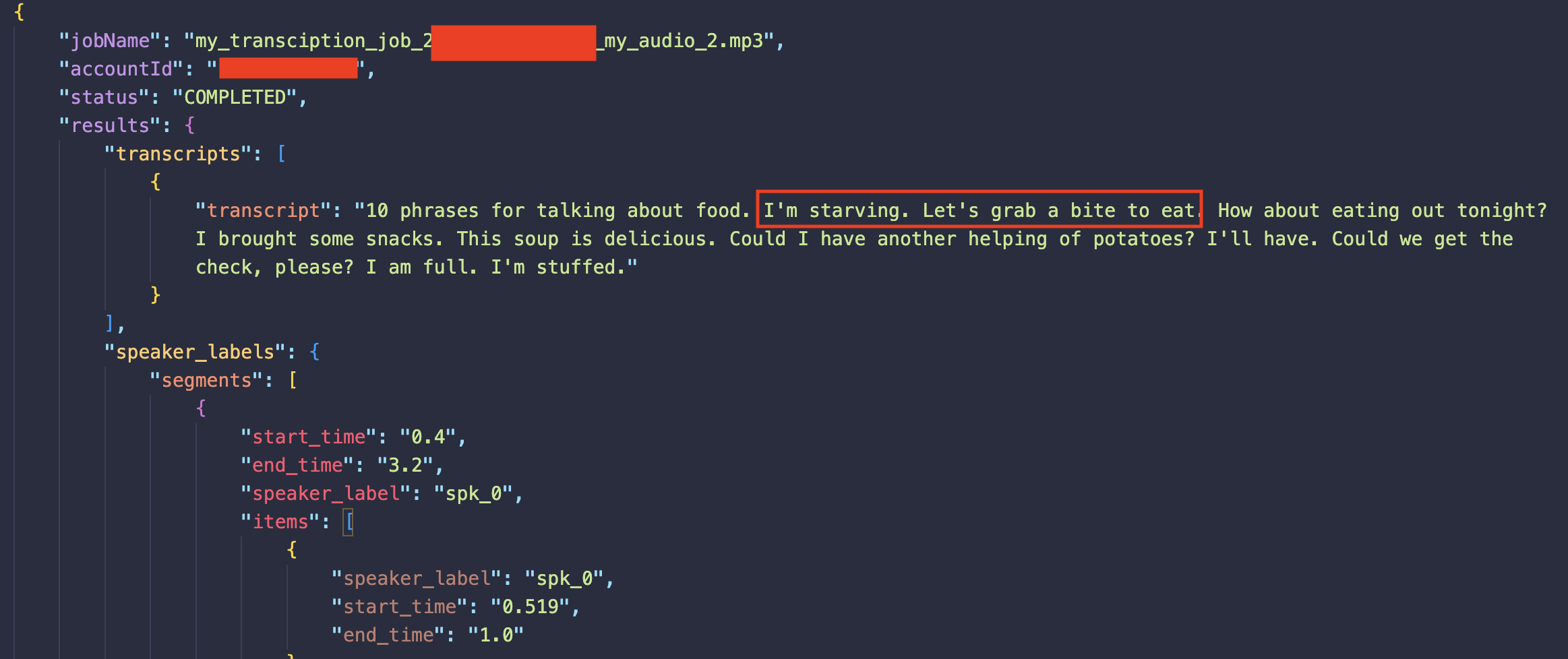
자막 파일은 위와 같이 JSON 파일 형식으로 생성된다. “I’m starving. Let’s grab a bite to eat.” 이 두 문장을 후에 이미지 생성 모델의 프롬프트로 입력할 것이다.
3. Bedrock을 실행하는 Lambda 함수 생성
베드락 서비스에 접속해 좌측 하단의 ‘모델 엑세스’를 클릭한다.
‘Modify model access’를 클릭한다.
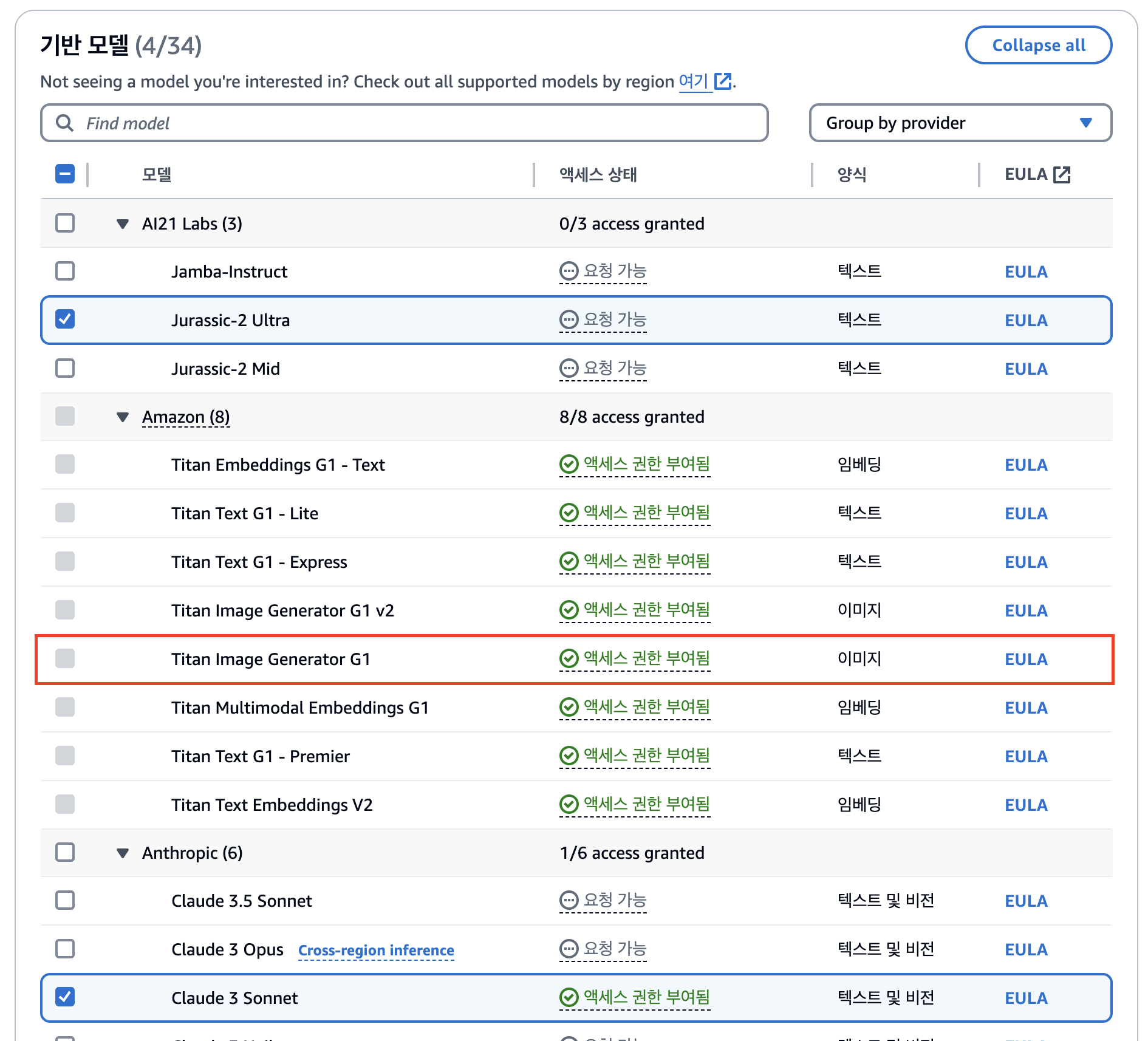
사용하고자 하는 모델에 체크박스를 선택하면 되는데, 여기선 Amazon - Titan Image Generator G1을 사용할 것이다.
사실 해당 모델은 기본 사용이 가능하므로 아마 체크가 안될 것이다. 만약 다른 모델을 써보고 싶다면 추가로 체크한다. (다만 이 글에서 다른 모델들의 파라미터 작성법까지 소개되진 않는다.)

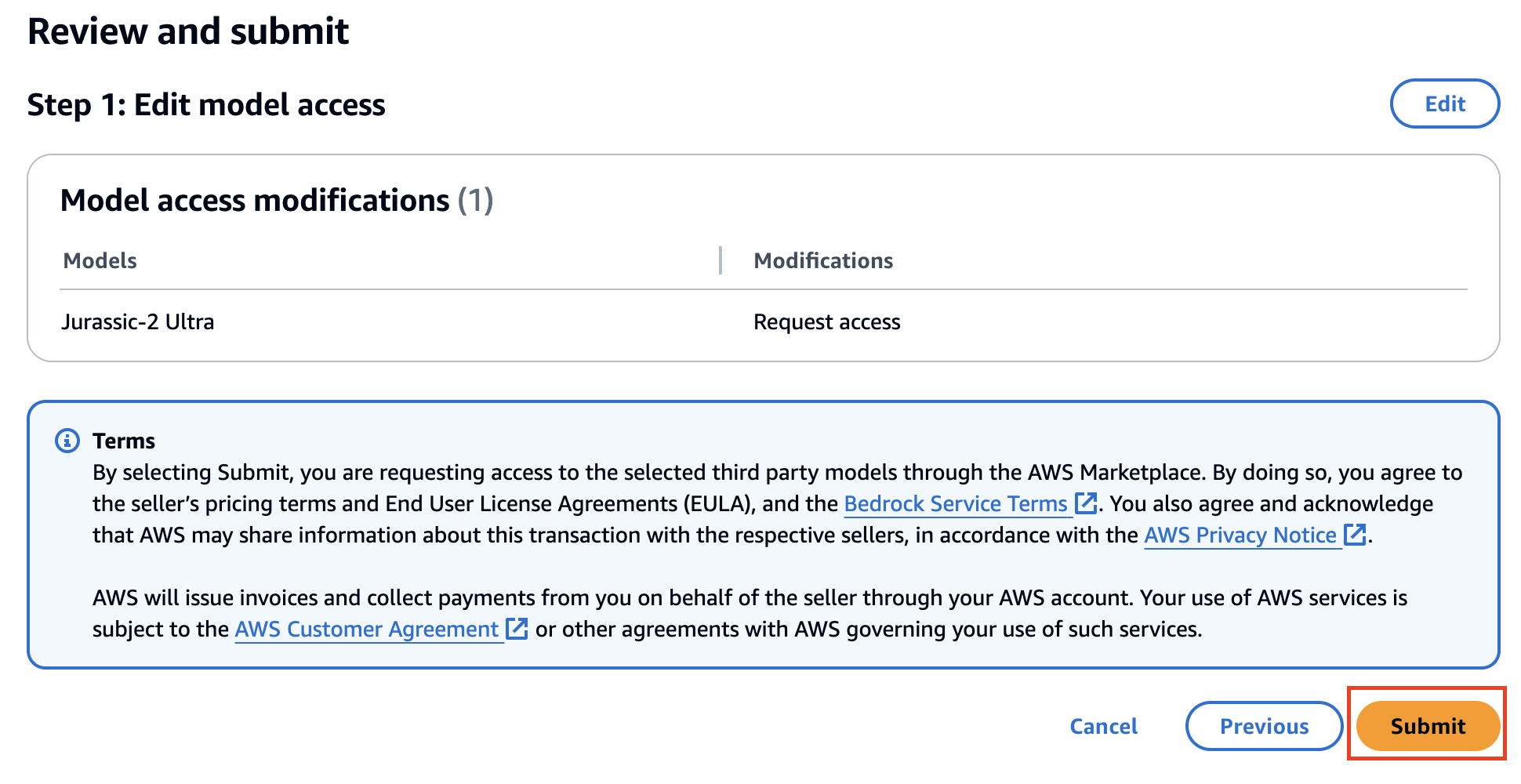
Next - Summit 순으로 클릭해 완료한다.
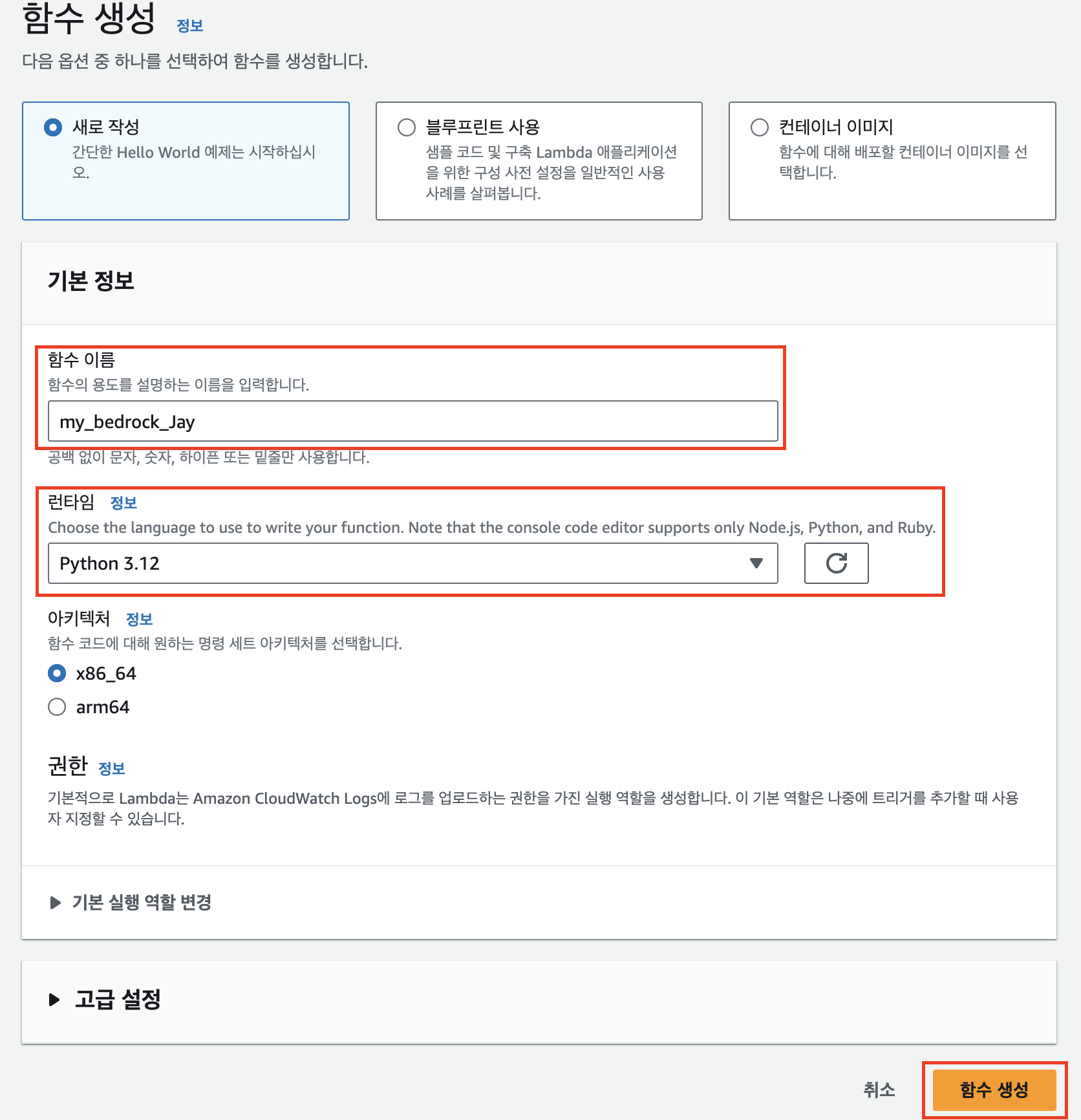
다시 Lambda 서비스로 돌아와, Bedrock과 관련된 이름으로 새 함수를 생성한다.
이후 과정은 앞서 Transcribe Lambda 함수 작성 과정과 거의 동일하기 때문에, 차이점 위주로만 설명한다.
- lambda_handler 코드
import json
import logging
import boto3
from botocore.exceptions import ClientError
import base64
# This creates a logger instance
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# This initializes the clients Bedrock Runtime and S3
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name='us-east-1')
s3 = boto3.client('s3')
def lambda_handler(event, context):
# We need to extract 'text' and 'seed' from the event, provide defaults if not present
bucket_name = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
s3_resource = boto3.resource('s3')
content_object = s3_resource.Object(bucket_name, key)
file_content = content_object.get()['Body'].read().decode('utf-8')
json_content = json.loads(file_content)
prompt = json_content["results"]["transcripts"][0]["transcript"]
prompt = '. '.join(prompt.split('. ')[1:3]) + '.'
logger.info(prompt)
##########################################
upload_bucket_name = Bucket-name-to-upload
##########################################
try:
base64_image_data = invoke_titan_image(prompt)
# The image data is a base64-encoded string, so we need to decode it to get the actual image data
image_data = base64.b64decode(base64_image_data)
object_key = "my_image_{}.jpg".format(key.split('.')[0].split('_')[-1])
# Now we upload the image data to S3
s3.put_object(
Bucket=upload_bucket_name,
Key=object_key,
Body=image_data,
ContentType='image/jpeg' # This is adjustable!
)
logger.info("Uploaded image to s3://{}/{}".format(upload_bucket_name, object_key))
return {
'statusCode': 200,
'body': json.dumps({'message': "Image uploaded successfully to {}/{}.".format(upload_bucket_name, object_key)})
}
except Exception as e:
logger.error("Error: %s", str(e))
return {
'statusCode': 500,
'body': json.dumps({'error': 'Failed to invoke model or upload image', 'detail': str(e)})
}
def invoke_titan_image(prompt):
try:
request = json.dumps({
"taskType": "TEXT_IMAGE",
"textToImageParams": {"text": prompt},
"imageGenerationConfig": {
"numberOfImages": 1,
"quality": "standard",
"cfgScale": 8.0,
"height": 640, # Permissible sizes: https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-titan-image.html#:~:text=The%20following%20sizes%20are%20permissible.
"width": 1408
},
})
response = bedrock_runtime_client.invoke_model(
modelId="amazon.titan-image-generator-v1", body=request
)
response_body = json.loads(response["body"].read())
base64_image_data = response_body["images"][0]
return base64_image_data
except ClientError as e:
logger.error("Couldn't invoke Titan Image generator: {}".format(e))
raise
- 트리거
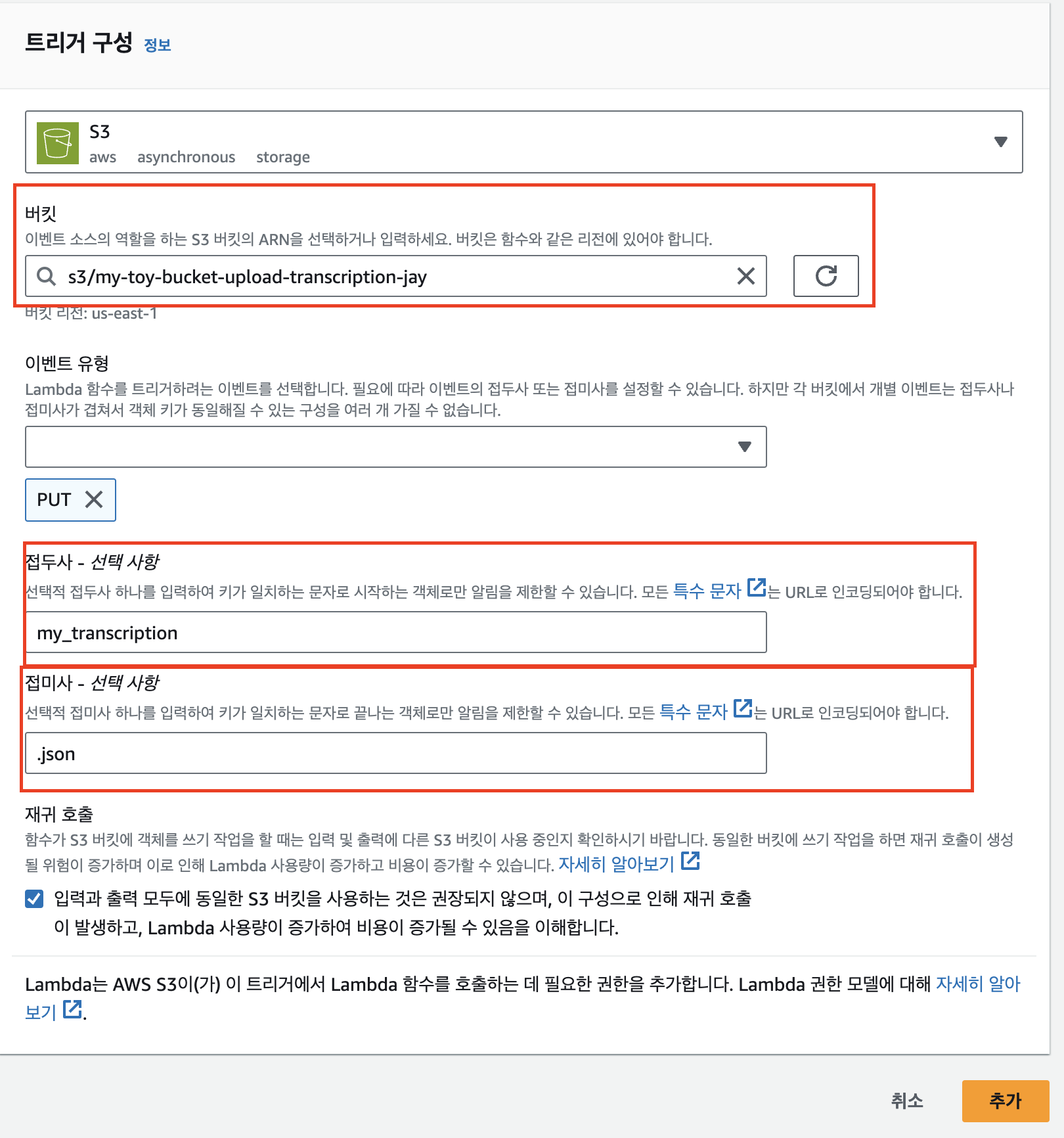
자막 파일이 업로드되는 버킷과 자막파일에 맞는 접두사, 접미사로 변경
- 실행 시간
동일하게 30초 이상으로 넉넉하게 설정
- 정책 설정
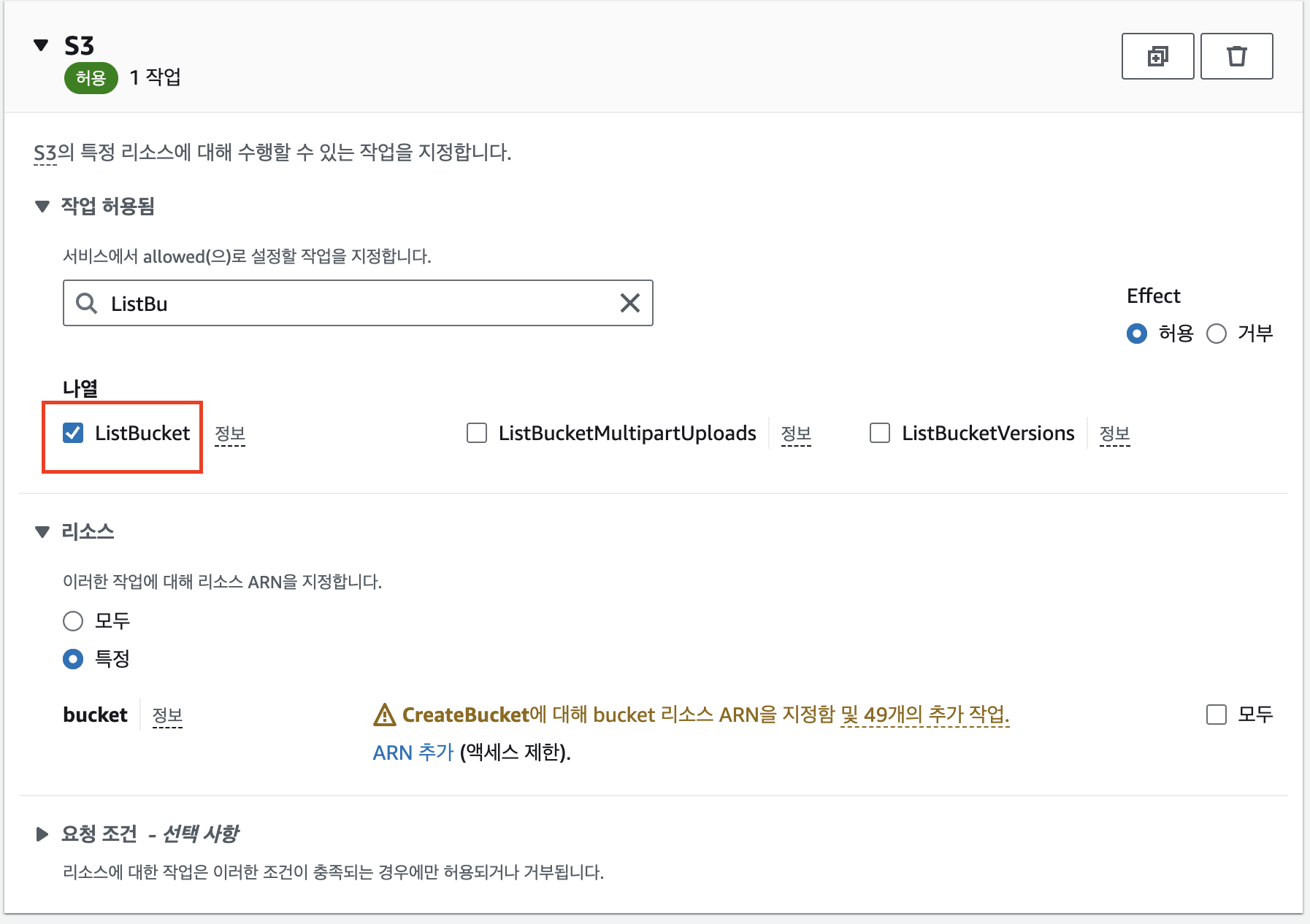
ARN 설정 없이 ListBucket 추가
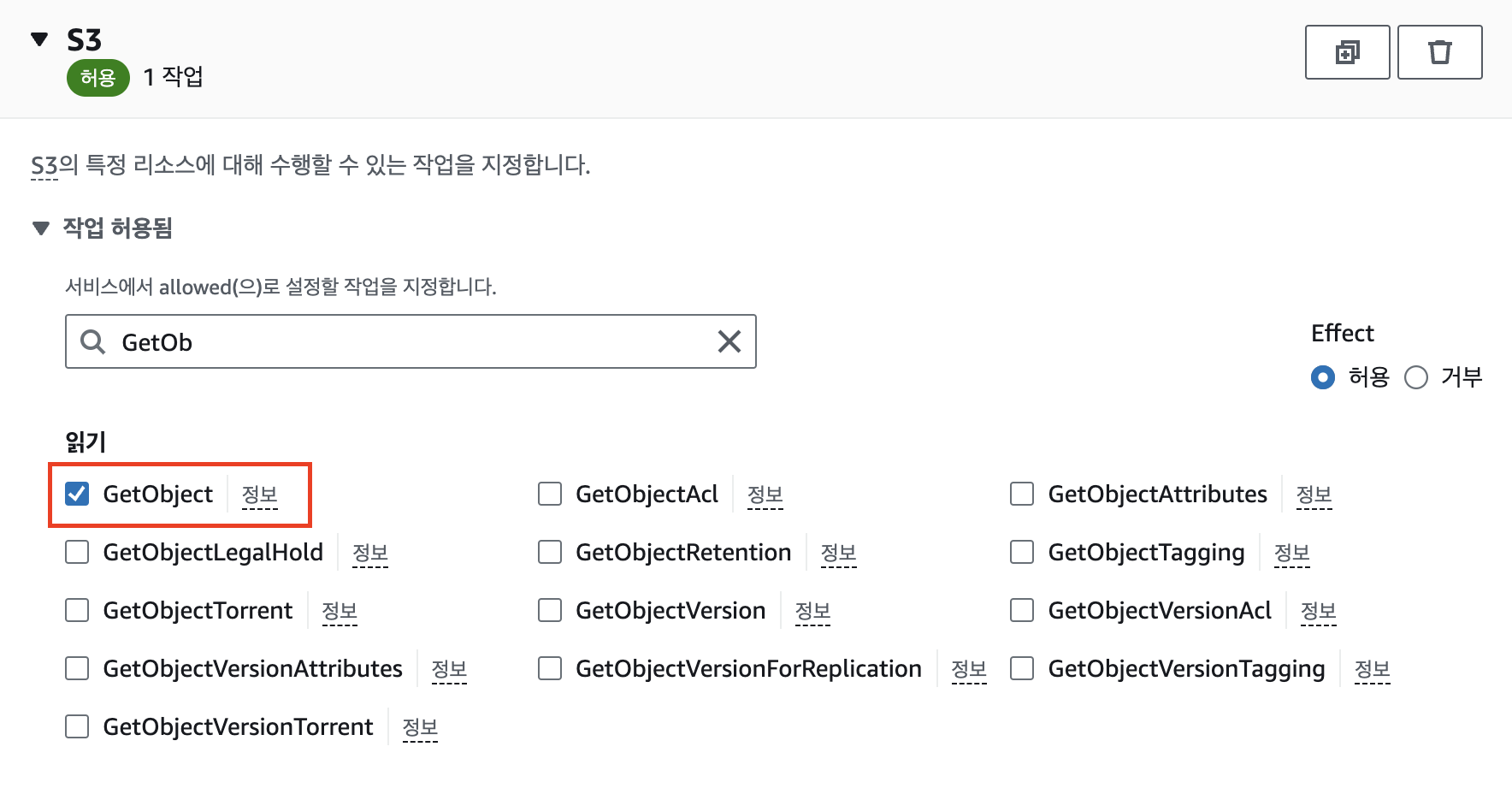
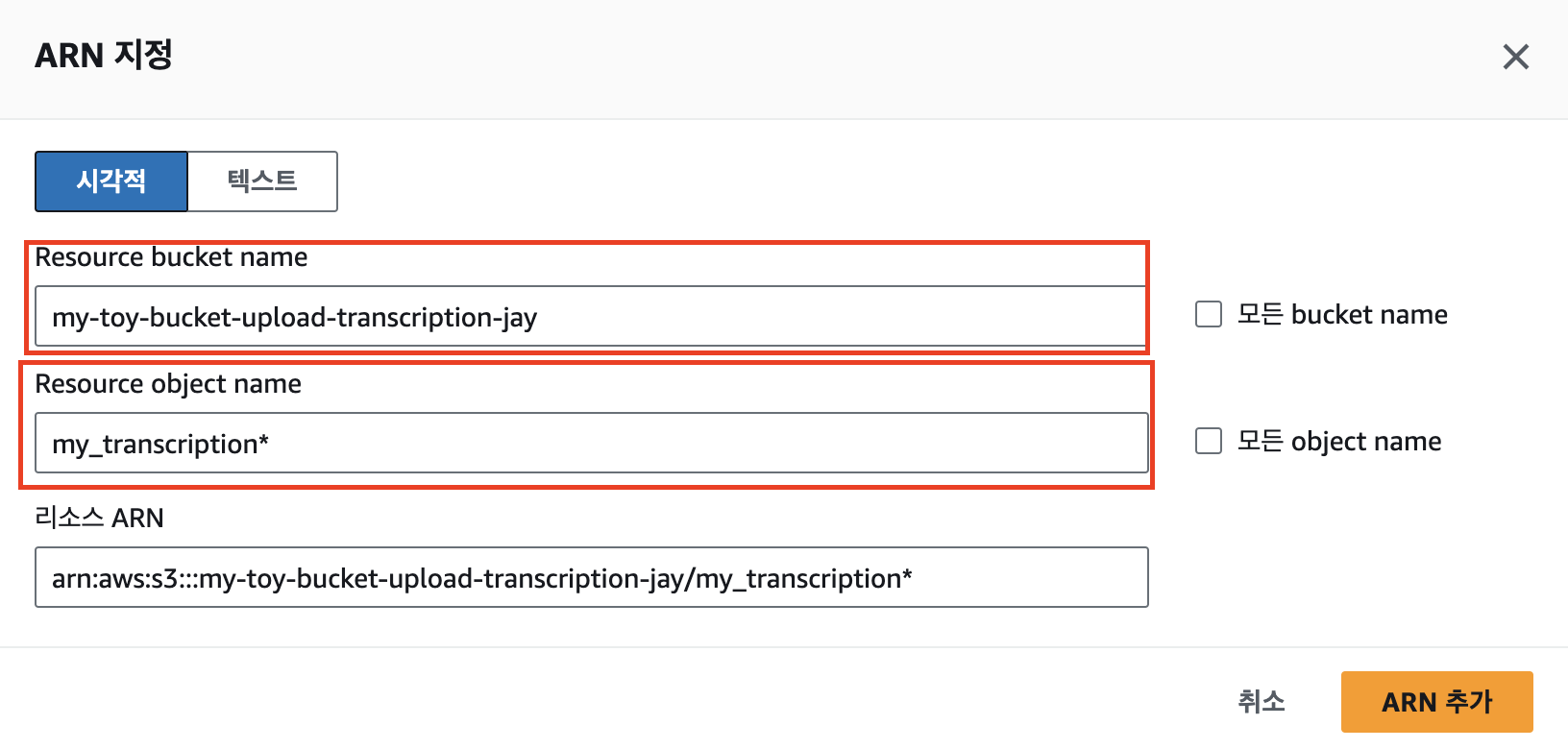
ARN은 자막 파일이 업로드되는 버킷에 맞게 설정하고, GetObject 추가
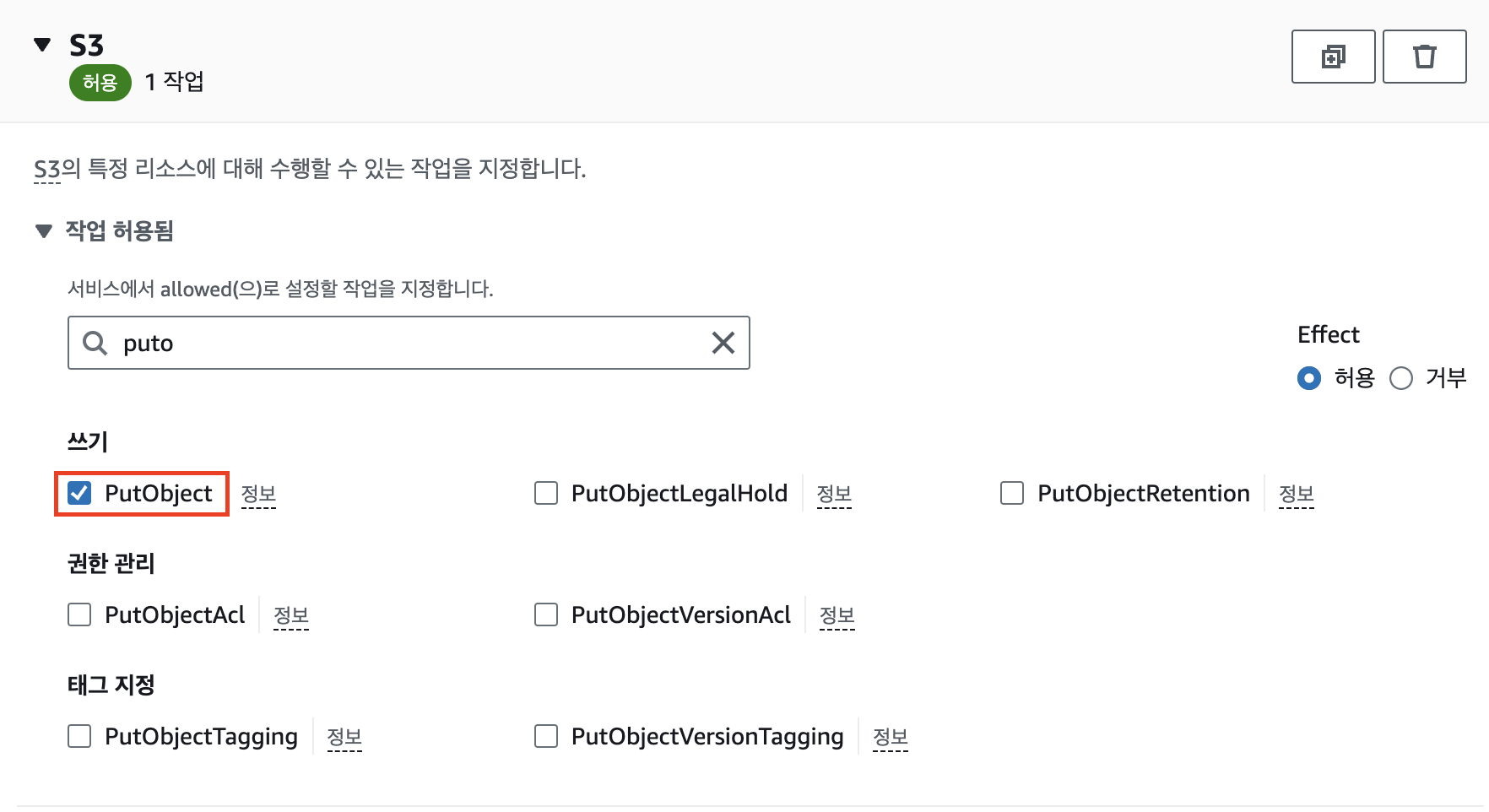
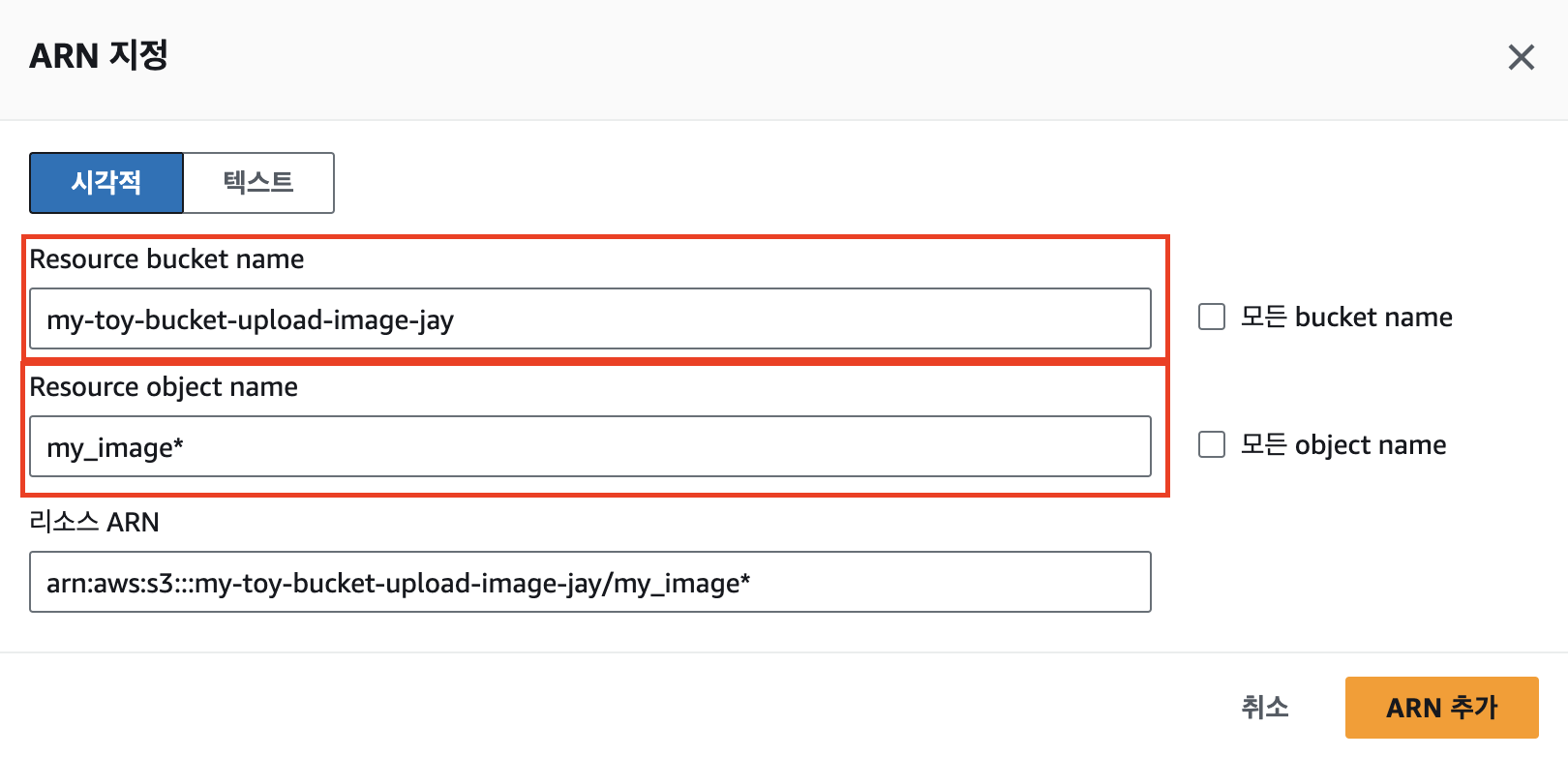
ARN은 이미지 파일이 업로드되는 버킷에 맞게 설정하고, PutObject 추가
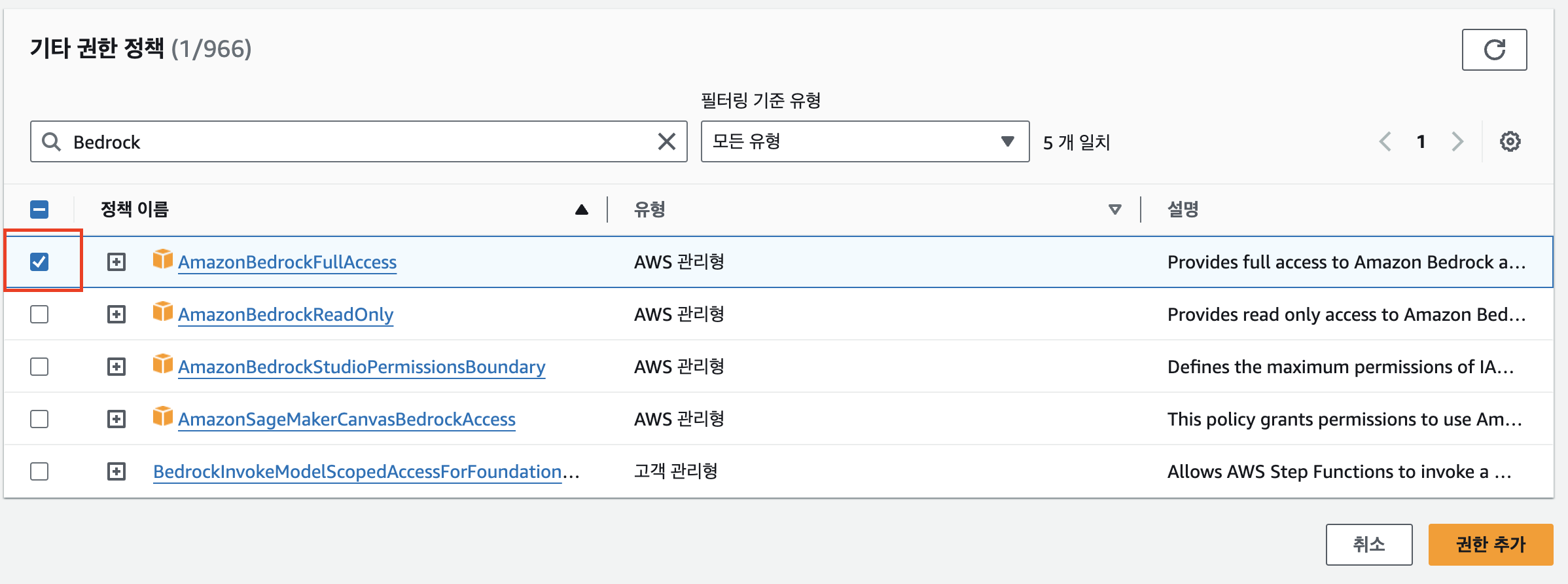
AmazonBedrockFullAccess 권한 추가

마찬가지로 Deploy 후 테스트 한번 실행해 CloudWatch 로그 그룹을 생성해준다. (테스트 실패해도 상관없음)
4. 테스트
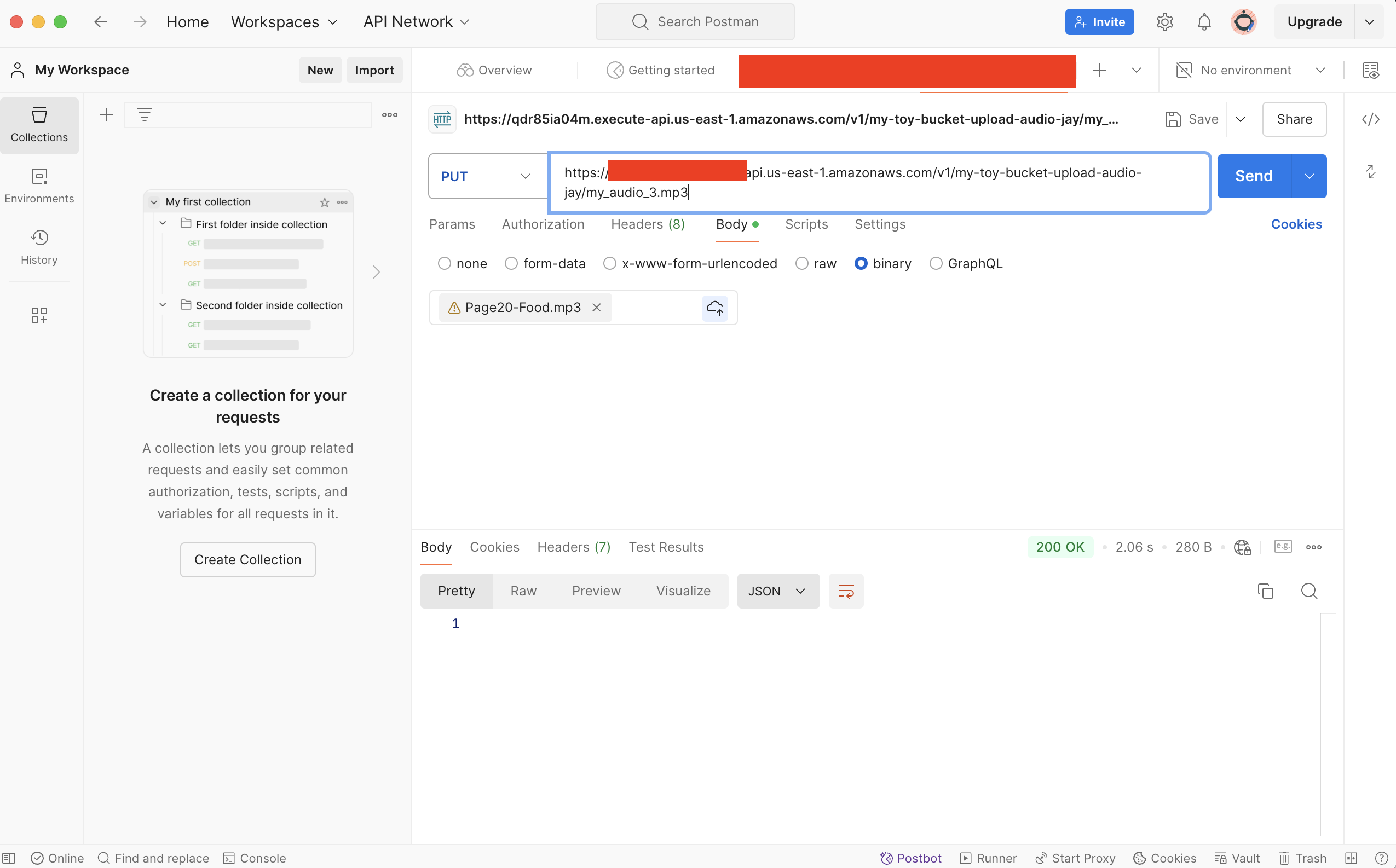
Postman으로 테스트 해보자.
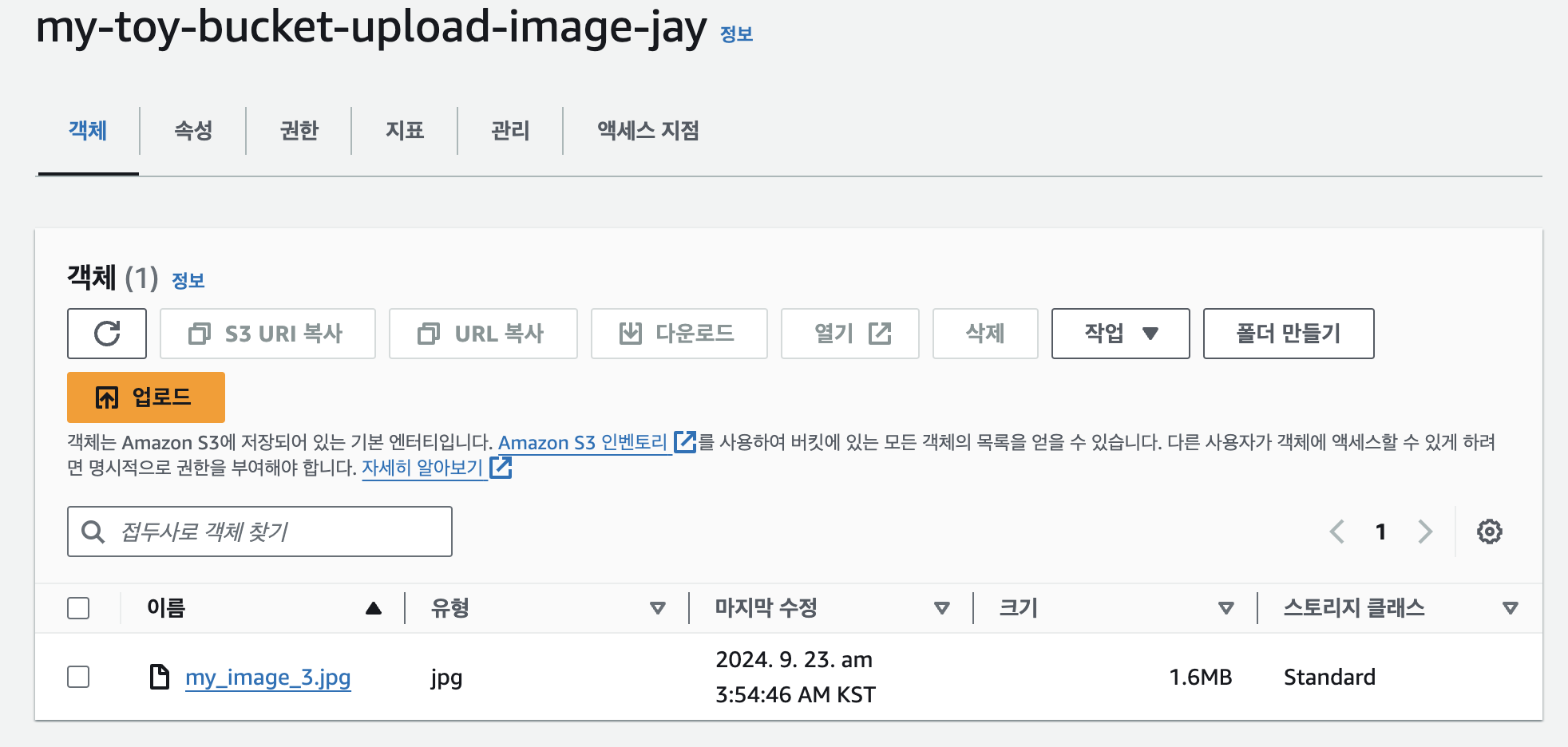
생성한 이미지 파일이 정상적으로 버킷에 존재하면 성공!

입력파일로 음식과 관련된 영어 대화 음성 파일을 사용했더니 결과물은 건초를 먹는 염소(?)가 나왔다.
구현에 집중한 토이 프로젝트라 결과물이 조금 재미 없는데, 여기에 프롬프트 엔지니어링을 잘 하고 좋은 입력 소스를 구한다면 재미있는 결과가 나올것 같다.
끝!
출처
- https://docs.aws.amazon.com/ko_kr/code-library/latest/ug/python_3_transcribe_code_examples.html
- https://docs.aws.amazon.com/ko_kr/bedrock/latest/userguide/titan-image-models.html
- https://community.aws/content/2byFjF8W1HHkzgis1aJokbXAJ6t/generate-and-store-images-in
'cloud' 카테고리의 다른 글
더보기| AWS Bedrock Tutorial - 음성파일로부터 자막과 이미지 생성하기(2) | 2024. 09. 22 |
|---|---|
| AWS Bedrock Tutorial - 음성파일로부터 자막과 이미지 생성하기(1) | 2024. 09. 22 |