gpt-oss tutorial(cpu에서 실행하기)

1. gpt-oss 개요
OpenAI는 2019년 이후 처음으로 가중치가 공개된 대형 언어 모델을 발표했다. 이름은 gpt-oss로, 두 가지 모델(20b, 120b)이 제공된다. 단순히 연구용 데모 수준이 아니라, 실제 환경에서 활용 가능한 고성능 모델을 누구나 내려받아 쓸 수 있다는 점에서 의미가 있다. (그리고 ClosedAI가 아닌 드디어 OpenAI가 됐다는 점에서도)
gpt-oss는 Transformer 기반 구조 위에 Mixture-of-Experts(MoE) 방식을 적용했다. 모든 토큰을 처리할 때 전체 파라미터가 동원되는 것이 아니라, 일부 전문가 집합만 활성화되어 연산 효율을 크게 높인다. 훈련시 4비트 양자화(MXFP4) 기법이 사용되었다. 또한 작업에 따라 reasoning effort 를 3단계로 설정할 수 있고 low로 설정시 매우 빠른 속도로 추론이 가능하다. 따라서 파라미터 규모가 크더라도 상대적으로 가벼운 리소스로 실행할 수 있다.
gpt-oss 20b 모델
gpt oss 20b는 약 210억 개의 파라미터를 가지고 있으며, 이 중 실제로 활성화되는 파라미터 수는 약 3.6억 개다. 이 모델의 가장 큰 특징은 16GB 메모리 환경에서도 실행 가능하다는 점이다.
즉, 최신 고성능 GPU 없이도 개인 PC나 엣지 디바이스에서 돌릴 수 있어 접근성이 매우 높다. 성능은 OpenAI의 o3-mini 모델과 유사한 수준으로 알려져 있으며, 일상적인 질의응답, 코드 작성, 간단한 추론 작업에 무리 없이 활용 가능하다.
gpt-oss 120b 모델
규모가 더 큰 120b 모델은 총 1,168억 파라미터를 갖고 있으며, 활성 파라미터는 약 51억 개다. 단일 80GB GPU(H100, MI300X 등)에서 구동할 수 있고, 성능은 o4-mini 모델에 근접한다.
주로 고사양 서버 환경에서의 대규모 추론이나 정밀한 작업을 위해 설계되었지만, 20b 모델과 동일하게 오픈 가중치로 제공되므로 연구·개발·커스터마이징에도 적합하다. 물론 PC나 서버에 많은 투자를 한게 아니라면 개인이 실행하는데에는 무리가 있다.
2. OpenAI Harmony 포맷
2-1. Harmony 포맷이란?

gpt-oss 모델은 Harmony 응답 포맷으로 학습되었으며, 포맷 없이 사용 시 올바르게 동작하지 않는다.
이 포맷은 OpenAI의 Responses API 구조를 모방해 설계되었으며, 대화 구조, 추론 흐름 (Chain-of-Thought), function 호출 구조화를 모두 포함한다.
쉽게 말해, 모델이 정형화된 포맷으로 답변을 생성하기 때문에 유저 입장에서 모델 출력결과가 최종 답변인지 함수 호출인지 등을 손쉽게 구분할 수 있고, 함수 호출이라면 함수명이 무엇이고 인자는 어떤 형태로 제공되는지 등을 바로 알 수 있다. 따라서 답변 형식을 따로 프롬프트 엔지니어링으로 사전에 정의하는 수고를 덜 수 있다.
2-2. 주요 구성 요소
역할 (Roles)
system: 정체성, 추론 수준, 메타 정보, 내장 도구 등을 지정developer: 시스템 프롬프트나 function tool 지침을 작성할 때 사용user: 사용자 입력assistant: 모델 출력 또는 도구(함수) 호출, 3개의 채널을 사용함.tool: function 도구 호출의 결과 메시지를 나타냄- 역할 계층:
system>developer>user>assistant>tool
채널 (Channels)
analysis: 모델의 추론 과정(CoT)을 담당하는 채널. 최종 사용자에게 노출되지 않도록 주의해야함.commentary: 도구(함수) 사용 요청을 보내고, 사용자로부터 받은 함수 실행 결과값을 처리하는 채널.final: 최종 출력을 담당하는 채널. 사용자에게 보여지는 메시지.
2-3. Harmony 렌더러 라이브러리
OpenAI는 Python 및 Rust용 공식 openai-harmony라이브러리를 제공하며, 이를 통해 올바른 포맷을 생성하고 토큰화할 수 있다. 다음은 harmony cookbook에서 볼 수 있는 대화 렌더링 예시이다. 총 6개의 메세지로 구성되어 있다. Identity(1번)와 시스템 프롬프트(2번)는 항상 앞에 위치하는 형식으로 시작된다. 유저의 질문(3번)을 어시스턴트가 질문의 의도를 분석해(4번) 함수 실행을 유저에게 요청하며 함수명과 인자를 제공(5번)한다. 마지막으로 실행된 함수의 결과값을 받아(6번) 처리한다.
# system_message, develper_message 정의하는 법은 cookbook 참조
convo = Conversation.from_messages(
[
# System Messege: Identity(모델 정체성)과 reasoning effort 등이 포함된다. 특히, 모델 정체성은 아래 문장을 바꾸지 말고 그대로 사용하라고 강조한다.
# You are ChatGPT, a large language model trained by OpenAI.
Message.from_role_and_content(Role.SYSTEM, system_message),
# Developer Messege: 시스템 프롬프트, 모델의 성격이나 역할, 룰 등을 정의하고 싶다면 이 부분에 정의하면 된다.
Message.from_role_and_content(Role.DEVELOPER, developer_message),
# 이 아래로는 user와 assistant간의 대화, 또는 assistant의 CoT, function call 등이 순차적으로 이어진다.
Message.from_role_and_content(Role.USER, "What is the weather in Tokyo?"),
Message.from_role_and_content(
Role.ASSISTANT,
'User asks: "What is the weather in Tokyo?" We need to use get_weather tool.',
).with_channel("analysis"),
Message.from_role_and_content(Role.ASSISTANT, '{"location": "Tokyo"}')
.with_channel("commentary")
.with_recipient("functions.get_weather")
.with_content_type("%3C|constrain|%3E json"),
Message.from_author_and_content(
Author.new(Role.TOOL, "functions.lookup_weather"),
'{ "temperature": 20, "sunny": true }',
).with_channel("commentary"),
]
)
tokens = encoding.render_conversation(convo)
convo_harmony = encoding.decode(tokens)
print(convo_harmony)
출력결과
<|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-08-21
Reasoning: high
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.<|end|><|start|>developer<|message|># Instructions
Always respond in riddles
# Tools
## functions
namespace functions {
// Gets the current weather in the provided location.
type get_current_weather = (_: {
// The city and state, e.g. San Francisco, CA
location: string,
format?: "celsius" | "fahrenheit", // default: celsius
}) => any;
} // namespace functions<|end|><|start|>user<|message|>What is the weather in Tokyo?<|end|><|start|>assistant<|channel|>analysis<|message|>User asks: "What is the weather in Tokyo?" We need to use get_weather tool.<|end|><|start|>assistant to=functions.get_weather<|channel|>commentary <|constrain|> json<|message|>{"location": "Tokyo"}<|call|><|start|>functions.lookup_weather<|channel|>commentary<|message|>{ "temperature": 20, "sunny": true }<|end|>'
render_conversation(Conversation)함수 대신 render_conversation_for_completion(Conversation, Role.ASSISTANT))함수 사용시 마지막에 추가로 <|start|>assistant|>토큰이 붙은 결과로 나온다. 모델 입력으로 사용시엔 꼭 후자로 사용해야만 답변이 정상적으로 생성된다. (assistant가 답변할 차례라는것을 명시적으로 가이드하는 역할)
2-4. Harmony 흐름 요약
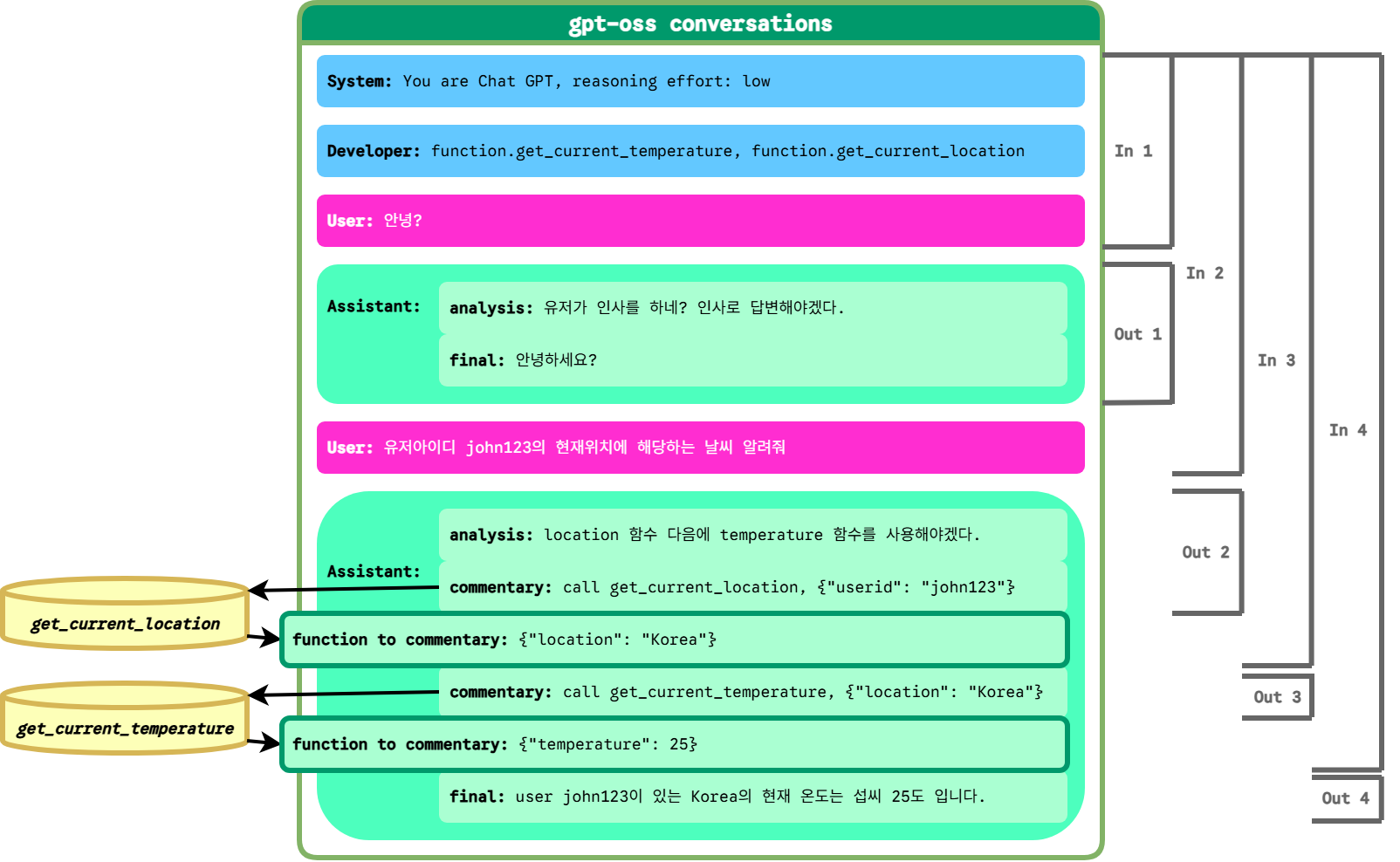
3. Unsloth 개요
3-1. Unsloth란?
Unsloth는 OpenAI의 gpt-oss를 포함한 다양한 LLM을 더 빠르고 효율적으로 실행, 튜닝 가능하게 해 주는 오픈소스 프레임워크이다.
3-2. Unsloth의 장점
- 경량화된 실행 환경: gpt-oss-20b는 약 14 GB VRAM으로 튜닝 가능하며, 120b는 65 GB로 충분하다.
- 파인튜닝 효율 개선: 일반 방식 대비 1.5× 빠른 학습, 70% VRAM 감소, 10× 긴 컨텍스트를 제공한다.
- 포맷 호환성 강화: GGUF, llama.cpp, Hugging Face, vLLM 등 다양한 플랫폼과 호환 가능
- Harmony 포맷 안정화: Unsloth의 chat template 수정으로 파싱 오류를 줄이고 안정성 확보
- 튜토리얼 제공: Colab 및 로컬 사용자를 위한 단계별 가이드와 안정적인 실행 흐름 제공
3-3. Unsloth에서 제공하는 gpt-oss 변형 모델
원본 gpt-oss는 mxfp4(4비트 양자화) 포맷만 지원하는데 반해, unsloth에서 제공하는 변형모델은 다양한 포맷과 양자화를 지원한다. 특히, mxfp4 포맷은 gpu에서만 실행할 수 있기 때문에 20b 모델 기준 최소 16gb vram gpu가 없는 pc에서는 로드조차 불가능한데, 변형모델 중 gguf 포맷으로 제공되는 버전은 llama.cpp를 활용해 cpu와 ram에서도 실행 가능하기 때문에 개인이 다루기에 아주 적합하다.
이 때문인지 허깅페이스에 올라온 다양한 gpt-oss 변형 모델 중 상위권을 차지하고 있다.
4. 튜토리얼
gpt oss를 로컬에서 실행하고, function call을 중심으로 간단한 채팅 워크플로우를 구성한 뒤, 앞에서 설명했던 예시인 유저의 현재 위치를 구하고 위치를 기반으로 기온을 구하는 워크플로우를 실행해본다. 마지막으론 실제로 내가 gpt-oss와 harmony를 다루면서 삽질한 경험을 바탕으로 모델 사용시 주의해야 하는 점을 정리했다.
4-1. gpt oss 20b CPU에서 실행하기
실행 환경
가상환경 생성이나 개발환경 세팅같은 내용은 생략하고, 현재 내가 사용중인 환경의 필수 패키지 버전만 작성했다.
- python version: 3.12
- requirements:
unsloth==2025.8.7 unsloth-zoo==2025.8.6 llama-cpp-python==0.3.16 openai-harmony==0.0.4
ram이 14gb정도 필요하므로 16gb, 여유있게 32gb ram 정도는 구매하는게 좋다.
gpt-oss-20b-F16.gguf 실행
import json
import unsloth
from llama_cpp import Llama
from unsloth_zoo import encode_conversations_with_harmony
from openai_harmony import (
Author,
Conversation,
DeveloperContent,
HarmonyEncodingName,
Message,
Role,
SystemContent,
ToolDescription,
load_harmony_encoding,
ReasoningEffort
)
# Model Loading
llm = Llama.from_pretrained(
repo_id="unsloth/gpt-oss-20b-GGUF",
filename="gpt-oss-20b-F16.gguf",
jinja=True,
n_ctx=16384, # unsloth recomendation
n_threads=20,
temp=1.0, # openai recomendation
top_p=1.0, # openai recomendation
top_k=0, # openai recomendation
verbose=False
)
딱히 설명이 더 필요 없을 정도로 너무 쉽게 실행됐다. unsloth_zoo를 import 하기 전에 unsloth를 미리 import 하는게 좋다. 이유는 잘 모르겠지만 나의 경우는 unsloth_zoo만 단독으로 import하면 unsloth를 내부적으로 import하지 못하는 문제가 있었다.
4-2. 대화 워크플로우 구성
필요 함수 사전 정의
모델이 사용할 함수를 우선 정의한다. 유저의 현재 위치를 기반으로 해당 위치의 온도를 구하는 대화를 할 계획이기 때문에 location을 구하는 함수, temperature를 구하는 함수 두개가 필요하다. 출력값은 각각 “Korea, Republic of”과 25로 고정해놨고 json 포맷으로 변환할 수 있게 dict로 반환한다.
def get_current_temperature(location, format_t='celcius'):
temperature = 25
return {"temperature": temperature}
def get_current_location(userid, max_len=10):
location = 'Korea, Republic of'
if len(location) > max_len:
location = location[:max_len]
return {"location": location}
func_map = {
"get_current_temperature": get_current_temperature,
"get_current_location": get_current_location
}
System Message, Developer Message 작성
원래라면 openai-harmony 패키지에서 제공하는 Conversation, Author, Message 같은 클래스를 사용해 작성해야 하지만, unsloth에서 제공하는 encode_conversations_with_harmony 함수를 사용한다면 이를 훨씬 쉽게 작성할 수 있다. 첫 유저 메세지는 시험삼아 “안녕”이라고 작성해보았다.
# 추론 수준: low, medium, high
reasoning_effort = "low"
# 인코딩 결과를 모델 입력으로 사용할지 여부
add_generation_prompt = True
# 함수 명세
tool_calls = [
{"function": {
"name": "get_current_temperature",
"description": "get current temperature based on current location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The Country, state or city, e.g. USA, CA, LA",
},
"format_t": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"default": "celsius",
},
},
"required": ["location"],
},
}},
{"function": {
"name": "get_current_location",
"description": "get current location based on user metadata",
"parameters": {
"type": "object",
"properties": {
"userid": {
"type": "string",
"description": "User's ID of current client session.",
},
"max_len": {
"type": "number",
"default": 10,
"description": "Max result length",
},
},
"required": ["userid"],
},
}},
]
# 개발자 지침 또는 시스템 프롬프트
developer_instructions = "If you don't know the answer just say that you don't know."
# 모델 정체성 (!!!변경하지 말고 그대로 쓰기!!!)
model_identity = "You are ChatGPT, a large language model trained by OpenAI."
encoded = encode_conversations_with_harmony(
[{"role": "user", "content": "안녕"}], # 대화내역
reasoning_effort = reasoning_effort,
add_generation_prompt = add_generation_prompt,
tool_calls = tool_calls,
developer_instructions = developer_instructions,
model_identity = model_identity
)
print(encoded[0])
출력결과
<|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-08-21
Reasoning: low
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.<|end|><|start|>developer<|message|># Instructions
If you don't know the answer just say that you don't know.
# Tools
## functions
namespace functions {
// get current weather based on current location
type get_current_temperature = (_: {
// The city and state, e.g. San Francisco, CA
location: string,
format_t?: "celsius" | "fahrenheit", // default: celsius
}) => any;
// get current location based on user metadata
type get_current_location = (_: {
// User's ID of current client session.
userid: string,
// Max result length
max_len?: number, // default: 10
}) => any;
} // namespace functions<|end|><|start|>user<|message|>안녕<|end|><|start|>assistant
출력결과 마지막이 <|start|>assistant로 끝나는데, 이는 add_generation_prompt=True로 설정했기 때문이다. false로 설정하면 저 부분이 추가되지 않는다. 모델 입력시 assistant가 대답할 차례라고 명시해주는 역할인데, 만약 이를 빼먹고 모델에 입력하면 출력결과에 문제가 생길 수 있다.
harmony encoding 정의
텍스트로 된 harmony 포맷을 객체 형태로 인코딩하거나 메세지 단위로 나누기 위해 필요하다.
allowed_special = {
'<|start|>', # 200006
'<|end|>', # 200007
'<|message|>', # 200008
'<|channel|>', # 200005
'<|constrain|>', # 200003
'<|return|>', # 200002
'<|call|>' # 200012
}
# Harmony Encoding
harmony_encoding = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
# From harmony format string To list of tokens
# 모델 입력이 아닌 메세지 파싱이 목적이므로 EOS 토큰이 마지막에 와야함. <|start|>assisant 빼기 위해 [:-18] 슬라이싱
tokens = harmony_encoding.encode(encoded[0][:-18], allowed_special=allowed_special)
# From list of tokens to list of Message
parsed_messages = harmony_encoding.parse_messages_from_completion_tokens(tokens, Role.ASSISTANT)
print(parsed_messages)
출력결과
[Message(author=Author(role=%3CRole.ASSISTANT: 'assistant'%3E, name=None), content=[TextContent(text="You are ChatGPT, a large language model trained by OpenAI.\nKnowledge cutoff: 2024-06\nCurrent date: 2025-08-21\n\nReasoning: low\n\n# Valid channels: analysis, commentary, final. Channel must be included for every message.\nCalls to these tools must go to the commentary channel: 'functions'.")], channel=None, recipient='<|start|>system', content_type=None), Message(author=Author(role=<Role.DEVELOPER: 'developer'>, name=None), content=[TextContent(text='# Instructions\n\nIf you don\'t know the answer just say that you don\'t know.\n\n# Tools\n\n## functions\n\nnamespace functions {\n\n// get current weather based on current location\ntype get_current_temperature = (_: {\n// The city and state, e.g. San Francisco, CA\nlocation: string,\nformat_t?: "celsius" | "fahrenheit", // default: celsius\n}) => any;\n\n// get current location based on user metadata\ntype get_current_location = (_: {\n// User\'s ID of current client session.\nuserid: string,\n// Max result length\nmax_len?: number, // default: 10\n}) => any;\n\n} // namespace functions')], channel=None, recipient=None, content_type=None), Message(author=Author(role=<Role.USER: 'user'>, name=None), content=[TextContent(text='안녕')], channel=None, recipient=None, content_type=None)]
대화 워크플로우 자동화 함수 작성
유저 입력과 대화 기록(user_message, conversation_history)를 입력받아 모델 최종 답변과 추가된 대화 기록(assistant_response, conversation_history)를 반환하는 함수를 작성한다.
실행 흐름은 다음과 같다.
- 대화 내역이 없으면 새 리스트 생성
- 마지막 대화 내역에 유저 입력 추가
- 대화내역 harmony 포맷으로 인코딩(conversation_harmony)
- 모델에 harmony 텍스트 입력 후 결과 반환
- 결과(response_harmony)를 list of Message 형태로 파싱해 for문 순회하며 차례로 대화내역에 저장. (중간 Message가 analysis channel인 경우 해당)
- 마지막 Message가 commentary channel인 경우 함수 이름과 인자를 받아 직접 함수 실행후 출력값 도출
- 시스템 프롬프트에 정의된 함수 명세와 유저 입력을 근거로 모델은 스스로 어떤 함수와 인자값이 필요한지 정할 수 있음
- 그러나, 모델이 함수를 스스로 실행하지는 못하므로 모델로부터 함수와 인자값을 받아 함수를 실행하는 코드가 반드시 필요함
- 함수 출력값을 포함한 메세지를 harmony 포맷으로 작성
- 대화내역 harmony + 결과 harmony + 함수 출력값 포함 메세지 harmony 를 다시 모델에 입력 및 함수 호출과 출력값까지 대화내역에 저장
- 10번에 도달할때까지 5~8번 반복
- 마지막 Message가 final channel인 경우 대화내역에 저장하고 유저에게 최종 입력값 제공
def get_response(user_message, conversation_history=None):
if conversation_history is None:
conversation_history = []
# Add user message to history
conversation_history.append({"role": "user", "content": user_message})
# From system prompt and sonversations to Harmony format
encoded = encode_conversations_with_harmony(
conversation_history,
reasoning_effort = reasoning_effort,
add_generation_prompt = add_generation_prompt,
tool_calls = tool_calls,
developer_instructions = developer_instructions,
model_identity = model_identity
)
conversation_harmony = encoded[0]
# conversation_tokens = encoded[1]
assistant_response = None
# Repeat until assistant final response is received
while assistant_response is None:
response = llm.create_completion(conversation_harmony, max_tokens=-1)
response_harmony = response["choices"][0]["text"].strip()
print("====== response harmony =======")
print(response_harmony)
try:
# response_harmony = '%3C|start|%3Eassistant' + response_harmony
tokens = harmony_encoding.encode(response_harmony, allowed_special=allowed_special)
parsed_messages = harmony_encoding.parse_messages_from_completion_tokens(tokens, Role.ASSISTANT)
print("======= parsed messages ======")
print(parsed_messages)
except:
raise RuntimeError(f"Failed to handle conversation: {response_harmony}")
for pm in parsed_messages:
# Add assistant function call and result to history
if pm.channel == "commentary":
func = pm.recipient[10:].strip() # functions. -> 10chars
args = json.loads(pm.content[0].text.strip())
if func is not None and args is not None:
result = func_map[func](**args) # run function
result_json = json.dumps(result)
conversation_harmony = ''.join([
conversation_harmony,
response_harmony,
'<|call|>',
f'<|start|>functions.{func} to=assistant<|channel|>commentary<|message|>{result_json}<|end|><start>assistant'
])
conversation_history.append({"role": "assistant", "tool_calls": [{"name": func, "arguments": json.dumps(args)}]})
conversation_history.append({"role": "tool", "name": func, "content": result_json})
# Add assistant thought to history
elif pm.channel == "analysis":
conversation_history.append({"role": "assistant", "content": pm.content[0].text, "thinking": ""})
# Add assistant answer to history
else: # pm.channel == "final"
assistant_response = pm.content[0].text
conversation_history.append({"role": "assistant", "content": assistant_response})
return assistant_response, conversation_history
대화 시작
response, conversation_history = get_response(
"유저 id가 john123인 사람의 현재 위치에 해당하는 곳의 현재 온도를 화씨로 알려줘. 그리고 그 온도라면 야외 활동하기에 어떤 상황인지도 대략적으로 설명해주고."
)
print(response)
중간출력
====== response harmony =======
<|channel|>analysis<|message|>Need to call get_current_location then get_current_temperature.<|end|><|start|>assistant<|channel|>commentary to=functions.get_current_location <|constrain|>json<|message|>{"userid":"john123","max_len":10}
======= parsed messages ======
[Message(author=Author(role=<Role.ASSISTANT: 'assistant'>, name=None), content=[TextContent(text='Need to call get_current_location then get_current_temperature.')], channel='analysis', recipient=None, content_type=None), Message(author=Author(role=<Role.ASSISTANT: 'assistant'>, name=None), content=[TextContent(text='{"userid":"john123","max_len":10}')], channel='commentary', recipient='functions.get_current_location', content_type='<|constrain|>json')]
====== response harmony =======
<|channel|>analysis<|message|>Now get temperature.<|end|><|start|>assistant<|channel|>commentary to=functions.get_current_temperature <|constrain|>json<|message|>{"location":"Korea, Rep","format_t":"fahrenheit"}
======= parsed messages ======
[Message(author=Author(role=<Role.ASSISTANT: 'assistant'>, name=None), content=[TextContent(text='Now get temperature.')], channel='analysis', recipient=None, content_type=None), Message(author=Author(role=<Role.ASSISTANT: 'assistant'>, name=None), content=[TextContent(text='{"location":"Korea, Rep","format_t":"fahrenheit"}')], channel='commentary', recipient='functions.get_current_temperature', content_type='<|constrain|>json')]
====== response harmony =======
<|channel|>final<|message|>현재 `john123`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25 °F**(섭씨 약 -3.9 °C)입니다.
**25 °F**는 상당히 추운 온도로, 실내에서 보온이 필요한 상황입니다.
- **야외 활동**: 25 °F에서는 장갑, 두꺼운 코트, 모자, 목도리 등 방한 장비가 필수입니다.
- **운동**: 조깅이나 자전거 타기 같은 유산소 운동은 몸이 차가워지기 쉽고, 근육이 경직될 수 있어 부상 위험이 높습니다.
- **일상 생활**: 외출 시 충분히 따뜻하게 입고, 기온 차가 큰 지역이라면 실내에서 휴식을 취하는 것이 좋습니다.
따라서, **야외 활동은 권장되지 않으며** 방한 준비가 충분히 된 뒤에야 짧은 시간 동안 밖에 나가야 할 필요가 있을 때 고려해 보시는 것이 좋습니다.
======= parsed messages ======
[Message(author=Author(role=<Role.ASSISTANT: 'assistant'>, name=None), content=[TextContent(text='현재 `john123`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25\u202f°F**(섭씨 약\u202f-3.9\u202f°C)입니다. \n\n**25\u202f°F**는 상당히 추운 온도로, 실내에서 보온이 필요한 상황입니다. \n\n- **야외 활동**: 25\u202f°F에서는 장갑, 두꺼운 코트, 모자, 목도리 등 방한 장비가 필수입니다. \n- **운동**: 조깅이나 자전거 타기 같은 유산소 운동은 몸이 차가워지기 쉽고, 근육이 경직될 수 있어 부상 위험이 높습니다. \n- **일상 생활**: 외출 시 충분히 따뜻하게 입고, 기온 차가 큰 지역이라면 실내에서 휴식을 취하는 것이 좋습니다. \n\n따라서, **야외 활동은 권장되지 않으며** 방한 준비가 충분히 된 뒤에야 짧은 시간 동안 밖에 나가야 할 필요가 있을 때 고려해 보시는 것이 좋습니다.')], channel='final', recipient=None, content_type=None)]
대화 워크플로우는 다음과 같이 흘러간다.
- user 입력에 대해 assistant가 analysis 채널에서 무엇을 해야하는지 스스로 생각 후 위치 구하는 함수가 필요하다는 것을 알아낸다.
- assistant가 전체 입력값을 근거로 함수명과 인자(get_current_location({“userid”: “john123”, “max_len”: 10}))를 정해 모델 외부에 제공한다. 1, 2번은 모델 내에서 연속적으로 이루어진다.
- 모델 외부의 함수 실행기에서 함수명과 인자를 받아 실행 후 출력값({“location”: “Korea, Rep”})을 다시 모델에 제공한다.
- 함수 실행기로부터 받은 출력값을 근거로 모델은 다시 analysis 채널에서 다음 행동을 생각한다. 이번엔 온도 구하는 함수가 필요하다는 것을 알아낸다.
- assistant가 전체 입력값을 근거로 함수명과 인자(get_current_temperature({“location”: “Korea, Rep”, “format_t”: “fahrenheit”}))를 정해 모델 외부에 제공한다. 4, 5번은 모델 내에서 연속적으로 이루어진다.
- 모델 외부의 함수 실행기에서 함수명과 인자를 받아 실행 후 출력값({“temperature”: 25})을 다시 모델에 제공한다.
- 함수 실행기로부터 받은 출력값을 근거로 모델은 final 채널에서 user에게 제공할 최종 답변을 생성한다.
최종출력
현재 `john123`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25 °F**(섭씨 약 -3.9 °C)입니다.
**25 °F**는 상당히 추운 온도로, 실내에서 보온이 필요한 상황입니다.
- **야외 활동**: 25 °F에서는 장갑, 두꺼운 코트, 모자, 목도리 등 방한 장비가 필수입니다.
- **운동**: 조깅이나 자전거 타기 같은 유산소 운동은 몸이 차가워지기 쉽고, 근육이 경직될 수 있어 부상 위험이 높습니다.
- **일상 생활**: 외출 시 충분히 따뜻하게 입고, 기온 차가 큰 지역이라면 실내에서 휴식을 취하는 것이 좋습니다.
따라서, **야외 활동은 권장되지 않으며** 방한 준비가 충분히 된 뒤에야 짧은 시간 동안 밖에 나가야 할 필요가 있을 때 고려해 보시는 것이 좋습니다.
이전 대화를 기억한 상태로 두번째 대화를 시작하려면 conversation_history를 같이 제공하면 된다.
response, conversation_history = get_response(
"그렇다면 유저 id가 jay_lee인 사람은?",
conversation_history=conversation_history
)
print(response)
최종결과
현재 `jay_lee`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25 °F**(섭씨 약 -3.9 °C)입니다.
**25 °F**는 매우 추운 온도이므로 야외 활동은 권장되지 않습니다. 방한 장비(두꺼운 코트, 모자, 장갑, 목도리 등)를 충분히 착용하고, 필요하다면 짧은 시간 동안 밖에 나가더라도 몸을 따뜻하게 유지하는 것이 중요합니다.
두 번의 연속된 대화에서 conversation_history는 다음과 같이 저장되었다. 이는 unsloth 인코더에 입력되는 포맷으로 harmony 렌더러를 사용할때보다 훨씬 간편한 형태인 것을 볼 수 있다.
# conversation_history
[{'role': 'user',
'content': '유저 id가 john123인 사람의 현재 위치에 해당하는 곳의 현재 온도를 화씨로 알려줘. 그리고 그 온도라면 야외 활동하기에 어떤 상황인지도 대략적으로 설명해주고.'}, # user
{'role': 'assistant',
'content': 'Need to call get_current_location then get_current_temperature.',
'thinking': ''}, # assistant analysis
{'role': 'assistant',
'tool_calls': [{'name': 'get_current_location',
'arguments': '{"userid": "john123", "max_len": 10}'}]}, # assistant commentary (function call)
{'role': 'tool',
'name': 'get_current_location',
'content': '{"location": "Korea, Rep"}'}, # function result to assistant commentary
{'role': 'assistant', 'content': 'Now get temperature.', 'thinking': ''}, # assistant analysis
{'role': 'assistant',
'tool_calls': [{'name': 'get_current_temperature',
'arguments': '{"location": "Korea, Rep", "format_t": "fahrenheit"}'}]}, # assistant commentary (function call)
{'role': 'tool',
'name': 'get_current_temperature',
'content': '{"temperature": 25}'}, # function result to assistant commentary
{'role': 'assistant',
'content': '현재 `john123`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25\u202f°F**(섭씨 약\u202f-3.9\u202f°C)입니다. \n\n**25\u202f°F**는 상당히 추운 온도로, 실내에서 보온이 필요한 상황입니다. \n\n- **야외 활동**: 25\u202f°F에서는 장갑, 두꺼운 코트, 모자, 목도리 등 방한 장비가 필수입니다. \n- **운동**: 조깅이나 자전거 타기 같은 유산소 운동은 몸이 차가워지기 쉽고, 근육이 경직될 수 있어 부상 위험이 높습니다. \n- **일상 생활**: 외출 시 충분히 따뜻하게 입고, 기온 차가 큰 지역이라면 실내에서 휴식을 취하는 것이 좋습니다. \n\n따라서, **야외 활동은 권장되지 않으며** 방한 준비가 충분히 된 뒤에야 짧은 시간 동안 밖에 나가야 할 필요가 있을 때 고려해 보시는 것이 좋습니다.'}, # assistant final
{'role': 'user', 'content': '그렇다면 유저 id가 jay_lee인 사람은?'}, # user
{'role': 'assistant', 'content': 'Need location then temp.', 'thinking': ''}, # assistant analysis
{'role': 'assistant',
'tool_calls': [{'name': 'get_current_location',
'arguments': '{"userid": "jay_lee", "max_len": 10}'}]}, # assistant commentary
{'role': 'tool',
'name': 'get_current_location',
'content': '{"location": "Korea, Rep"}'}, # function result to assistant commentary
{'role': 'assistant',
'tool_calls': [{'name': 'get_current_temperature',
'arguments': '{"location": "Korea, Rep", "format_t": "fahrenheit"}'}]}, # assistant commentary, 첫번째 대화와 다르게 analysis를 거치지 않고 바로 function call을 한다.
{'role': 'tool',
'name': 'get_current_temperature',
'content': '{"temperature": 25}'}, # function result to assistant commentary
{'role': 'assistant',
'content': '현재 `jay_lee`님의 위치는 **대한민국**이며, 해당 지역의 현재 기온은 **25\u202f°F**(섭씨 약\u202f-3.9\u202f°C)입니다. \n\n**25\u202f°F**는 매우 추운 온도이므로 야외 활동은 권장되지 않습니다. 방한 장비(두꺼운 코트, 모자, 장갑, 목도리 등)를 충분히 착용하고, 필요하다면 짧은 시간 동안 밖에 나가더라도 몸을 따뜻하게 유지하는 것이 중요합니다.'}] # assistant final
4-3. troubleshooting
harmony encoding 파싱 오류
harmony 문서에서 parse_messages_from_completion_tokens함수가 제대로 동작하지 않을 때를 대비해 예외처리를 권장하고 있다.
The bindings raise plain Python exceptions. The most common ones are:
RuntimeError– returned for rendering or parsing failures (for example if a token sequence is malformed or decoding fails).ValueError– raised when an argument is invalid, e.g. an unknownRoleis provided toload_harmony_encodingorStreamableParser.ModuleNotFoundError– accessing the package without building the compiled extension results in this error.
In typical code you would wrap encoding operations in a try/except block:
try:
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
parsed = enc.parse_messages_from_completion_tokens(tokens, Role.ASSISTANT)
except RuntimeError as err:
print(f"Failed to handle conversation: {err}")
가장 중요한 RuntimeError의 경우 시작 토큰이 없거나 종료 토큰이 없는 경우, 시작 토큰 뒤에 role이 아닌 channel이 오는 경우 등등 harmony 형식에서 어긋난 토큰 순서를 만나면 발생한다.
만약 모델에서 생성된 결과가 harmony 포맷에서 어긋난다면, 앞부분에서도 강조했듯이 가장 먼저 모델 입력값에 <|start|>assistant를 붙이고 모델에 입력했는지를 꼭 확인해봐야 한다. 만약 붙이지 않고 입력한다면 다음과 같이 시작 토큰 뒤에 채널명이 생성되어버리는 대참사가 종종 발생한다.
# malformed harmony example
<|start|>analysis<|message|>Need to call get_current_location then get_current_temperature.<|end|>
llama.cpp에서 stop token을 제공하지 않는 문제
스페셜 토큰 중 두 개의 stop token이 있는데, <|call|>과 <|return|>이다. 문제는 llama 모델의 create_completion 함수 실행후 나오는 결과 값에 제공되는 생성 종료 사유에 둘 중 어떤 토큰으로 종료되었는지를 알려주지 않고 해당 stop token을 제거한채로 결과를 줘버린다.
멈춘 사유를 모른다면 두 토큰 중 어떤 토큰을 사용해야하는지 어떻게 알까? 다행히 <|return|>토큰은 직접 사용할 일이 없다. 해당 토큰은 모델의 출력값으로만 사용되기에 어차피 다음 입력으로 포함되면 안되기 때문. 또한 encode_conversations_with_harmony함수가 <|return|>이 들어갈 위치에 알아서 <|end|>를 채워준다.
따라서 위에 작성된 get_response 함수 내부에서 function call의 결과를 다시 모델에 제공할 때 강제로 <|call|> 토큰을 올바른 위치에 붙여주는 것만 신경쓰면 된다.
conversation_harmony = ''.join([
conversation_harmony,
response_harmony,
'<|call|>', # 삭제된 stop token 강제로 추가
f'<|start|>functions.{func} to=assistant<|channel|>commentary<|message|>{result_json}<|end|><start>assistant'])
harmony 문서에는 다음과 같이 언급되어있다.
Implementation note: <|return|> is a decode-time stop token only. When you add the assistant’s generated reply to conversation history for the next turn, replace the trailing <|return|> with <|end|> so that stored messages are fully formed as <|start|>{header}<|message|>{content}<|end|>. Prior messages in prompts should therefore end with <|end|>. For supervised targets/training examples, ending with <|return|> is appropriate; for persisted history, normalize to <|end|>.
5. 총평
- gguf포맷으로 cpu에서 충분히 실행할 수는 있으나 실시간성으로 쓰기엔 많이 느리다. (한번 생성에 분 단위 소요)
- unsloth에서 harmony 렌더러 wrapping해서 제공해준 함수가 기대이상으로 쓰기 간편하다
- harmony 포맷이 구조화가 잘 되어있어 모델이 토큰을 생성하는 순서를 체계적으로 이해할 수 있고 모델 외부와 높은 확률로 오류 없이 결과를 주고받을 수 있는 점이 맘에 든다
- moe 레이어만 cpu에서 실행하고 나머지는 gpu에서 실행할 수 있다는데 (llama –cpu-moe 옵션) 한번 쓸만한지 테스트해보면 좋을듯
출처
- https://openai.com/ko-KR/index/introducing-gpt-oss/
- https://github.com/openai/gpt-oss
- https://github.com/openai/harmony
- https://cookbook.openai.com/articles/openai-harmony
- https://docs.unsloth.ai/basics/gpt-oss-how-to-run-and-fine-tune
- https://huggingface.co/openai/gpt-oss-20b
'llm' 카테고리의 다른 글
더보기| gpt-oss tutorial(cpu에서 실행하기) | 2025. 08. 20 |
|---|