M1 맥 GPU 가속 지원하는 텐서플로우 개발환경 세팅

M1pro 맥북프로 14인치를 질렀다.
Mac OS는 처음이라 익숙치 않아 2~3일 정도는 설정을 만지작거렸고, 이후에 딥러닝 개발 환경 세팅을 시작했다.
아직까지 애플 실리콘에선 완벽한 딥러닝 환경을 구현하기엔 무리가 있지만, 적어도 텐서플로우는 공식적으로 GPU가속을 지원한다.
개발환경 세팅을 위해 인터넷에 올라온 여러 글을 참고했는데, 여러번 설치에 실패했다.
결국 돌고 돌아 애플 공식 개발자 가이드에 소개된 내용이 정답이었다
주의사항
- 파이썬 버전 3.8 또는 3.9 필요
- Conda 설치 금지
- Homebrew 사용 금지
우선 이 글을 보는 누군가의 삽질을 막기 위해 주의사항으로 시작한다. 자세한 이유는 아래에서 설명한다.
만약 이미 Anaconda나 Conda를 설치했다면 가능하면 삭제 후에 진행하자.
Conda 삭제방법 가장 추천수 많이 받은 답변 참고
추가로 내 경우는 아나콘다가 /opt/anaconda3 에도 설치되었다. 각자 아나콘다가 삭제된 폴더를 잘 찾아서 싹 다 삭제해주자
환경설정
Miniforge 설치용 쉘 스크립트 파일을 다운로드 받는다. 링크
Miniforge는 Conda와 비슷한 파이썬 패키지 및 가상환경 관리 플랫폼이다. Conda를 사용하지 않는 이유는 애플 실리콘을 지원하지 않기 때문이고, 텐서플로우의 GPU가속 플러그인 tensorflow-metal이 이 miniforge채널을 통해서만 배포되기 때문이다.
아래 명령어로 설치를 진행한다.
$ chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
$ sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
$ source ~/miniforge3/bin/activate
여기부턴 가상환경(base)이 실행된 상태가 된다.
Miniforge 설치 중 환경변수 이름을 conda로 사용할 거냐고 묻는 메세지가 중간에 나오는데, 십중팔구는 Yes를 선택할 것이다.
이러면 기존에 설치된 conda랑 환경변수가 겹칠 수 있으니, 애플 실리콘 지원 안해주는 conda를 처음부터 삭제하고 설치하는 것이 낫다.
설치확인
(base)$ conda info
>>>
active environment : None
shell level : 0
...
platform : osx-arm64
user-agent : conda/4.11.0 requests/2.27.1 CPython/3.9.10 Darwin/21.4.0 OSX/12.3
UID:GID : 000:00
netrc file : None
offline mode : False
중간에 platform에 ‘osx-arm64’로 표기되어 있어야 성공이다. ‘osx-64’ 이렇게 표기되면 실패한거니 삭제 후 다시 설치하자.
Homebrew를 사용하지 말라는 이유가 여기 있다. Miniforge는 쉘 스크립트 파일 다운받고 명령어 여러줄 칠 필요 없이 Homebrew만으로도 간편하게 설치가 가능한데, 이렇게 설치하면 애플 실리콘 버전이 아닌 인텔 버전이 설치된다. 일단 적어도 내 경우에는 그랬다.
텐서플로우 dependencies 설치
(base)$ conda install -c apple tensorflow-deps
텐서플로우 설치
(base)$ python -m pip install tensorflow-macos
텐서플로우 metal 플러그인 설치
(base)$ python -m pip install tensorflow-metal
디바이스 선택
텐서플로우 2.8에선 MLIR 이라는 채-신 기술을 사용해 디바이스를 자동으로 선택해준다. 따로 설정할 필요 없음
Multi-Level Intermediate Representation, 다중 계층에서 파편화된 딥러닝의 표현방식, 컴파일러, 프레임워크, 실행 환경 등을 일반화하고 통합하는 프로젝트라고 하는데, 다음에 자세히 알아봐야겠다.
테스트
MNIST 예제 코드
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
실행 결과
Metal device set to: Apple M1 Pro
systemMemory: 32.00 GB
maxCacheSize: 10.67 GB
2022-03-18 00:46:54.141153: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-03-18 00:46:54.141252: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
2022-03-18 00:46:54.273304: W tensorflow/core/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
Epoch 1/5
2022-03-18 00:46:54.409370: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
1875/1875 [==============================] - 9s 5ms/step - loss: 0.2959 - accuracy: 0.9148
Epoch 2/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1403 - accuracy: 0.9587
Epoch 3/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1023 - accuracy: 0.9689
Epoch 4/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.0803 - accuracy: 0.9753
Epoch 5/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.0680 - accuracy: 0.9789
2022-03-18 00:47:38.664373: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
313/313 - 1s - loss: 0.0706 - accuracy: 0.9771 - 1s/epoch - 4ms/step
디바이스가 Apple M1 Pro로 제대로 인식되었다
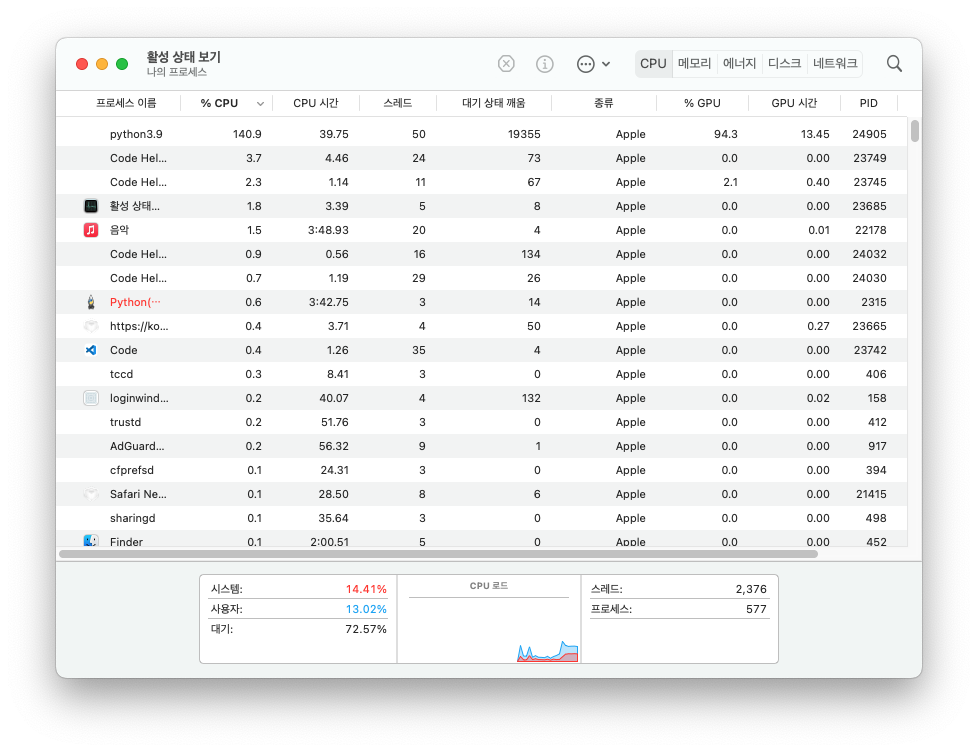
또한 GPU 활성 상태도 90% 이상으로 성능을 잘 활용하는 것을 확인했다.
기타
파이토치는 애플 실리콘 네이티브를 지원하지만 아직까지 GPU가속 지원은 개발중이라고 한다.
개인적으로 따로 쓸 수 있는 GPU 서버가 없다면 구글 코랩이나 Paperspace Gradient같은 클라우드 딥러닝 플랫폼을 사용하는걸 권한다.
출처
'mac_os' 카테고리의 다른 글
더보기| (MacOS) Vim을 기본 텍스트 에디터로 사용하기 | 2022. 03. 22 |
|---|---|
| M1 맥 GPU 가속 지원하는 텐서플로우 개발환경 세팅 | 2022. 03. 17 |