(MLOps) MLFlow 기초 - 모델 배포 및 쿼리

이 글은 에이콘 출판사의 ‘MLFlow를 활용한 MLOps’ 도서의 내용을 참고해 작성되었습니다.
붓꽃 분류 모델 배포하기
지난 포스트 MLFlow로 붓꽃 분류 모델 로깅하기에서 이어진다.
이번 포스트에선 저장된 모델을 배포하고 쿼리문으로 POST request를 작성해 inference를 수행하는 방법에 대해 알아본다.
데이터 로드 및 스케일링
필요한 패키지를 불러온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score, confusion_matrix
import subprocess
import json
붓꽃 데이터를 불러온다.
iris = load_iris()
iris_data = pd.DataFrame(data=np.c_[iris['data'], iris['target']], columns=iris['feature_names']+['target'])
x_data = iris_data.iloc[:, :-1]
y_data = iris_data.iloc[:,[-1]]
타겟별로 데이터를 구분하고, 스케일러를 Fitting한다.
현재 예제에서는 스케일러를 새로 정의했지만, 이런 Fitting이 필요한 오브젝트들은 훈련 후 같이 파이프라인에 저장해서 Inference 과정을 자동화 할 수 있다.
setosa = iris_data[iris_data.target == 0.0]
versicolor = iris_data[iris_data.target == 1.0]
virginica = iris_data[iris_data.target == 2.0]
scaler = StandardScaler()
scaler.fit(pd.concat((setosa.sample(frac=0.5), versicolor.sample(frac=0.5), virginica.sample(frac=0.5))).drop('target', axis=1))
입력데이터에서 타겟을 분리시키고, 스케일러에 입력시켜 표준화한다.
데이터프레임을 json으로 변환할 때 현재 코드에선 “split” 형식으로 변환했다.
x_input = pd.concat((setosa_train, versicolor_train, virginica_train)).sample(n=20)
y = np.array(x_input['target'])
x_input.drop('target', axis=1, inplace=True)
x_input = pd.DataFrame(scaler.transform(x_input)).to_json(orient="split")
모델 배포
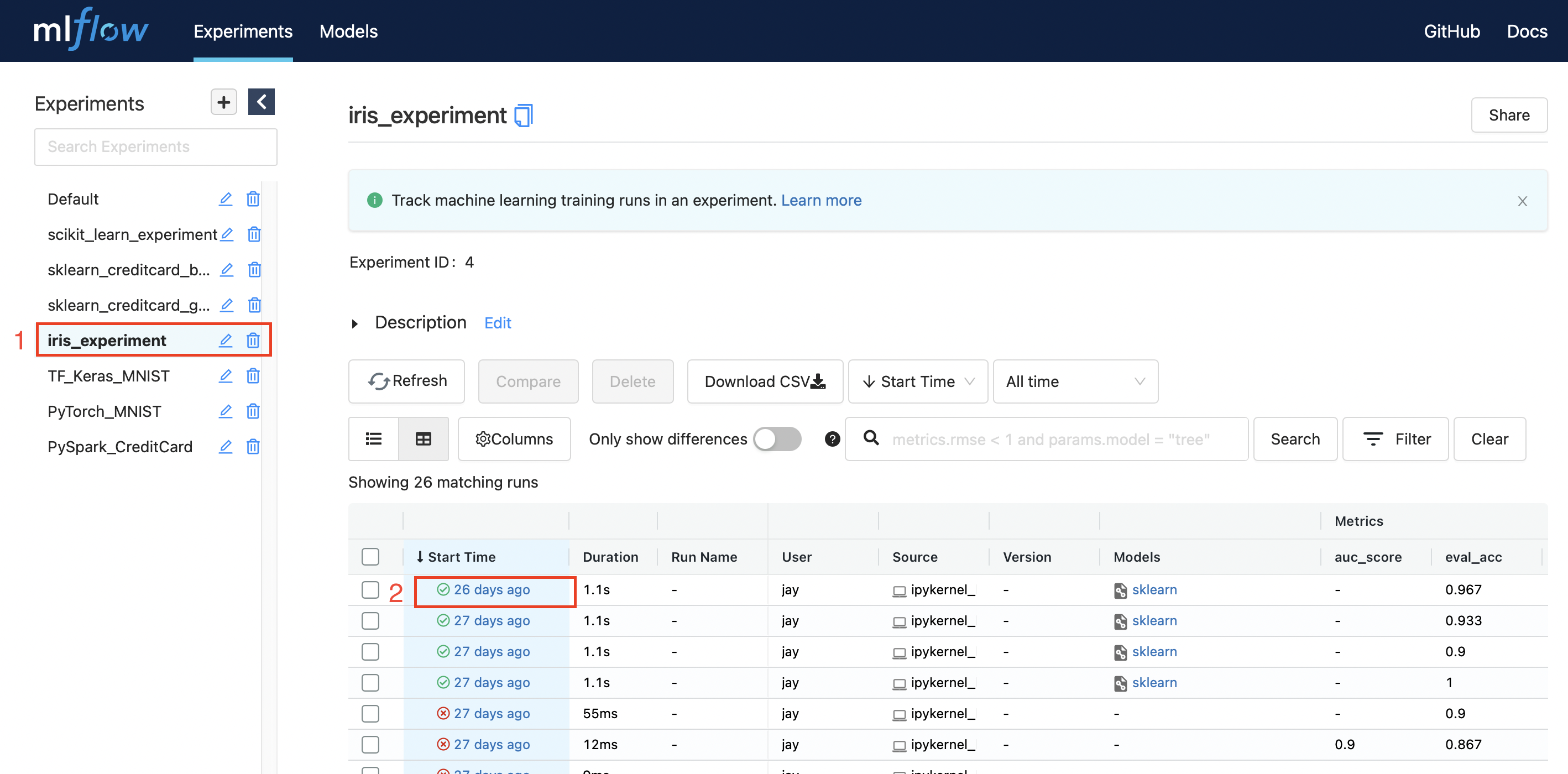
이제 ui 서버를 열고 저장된 모델을 클릭한다.
mlflow ui -p 1234
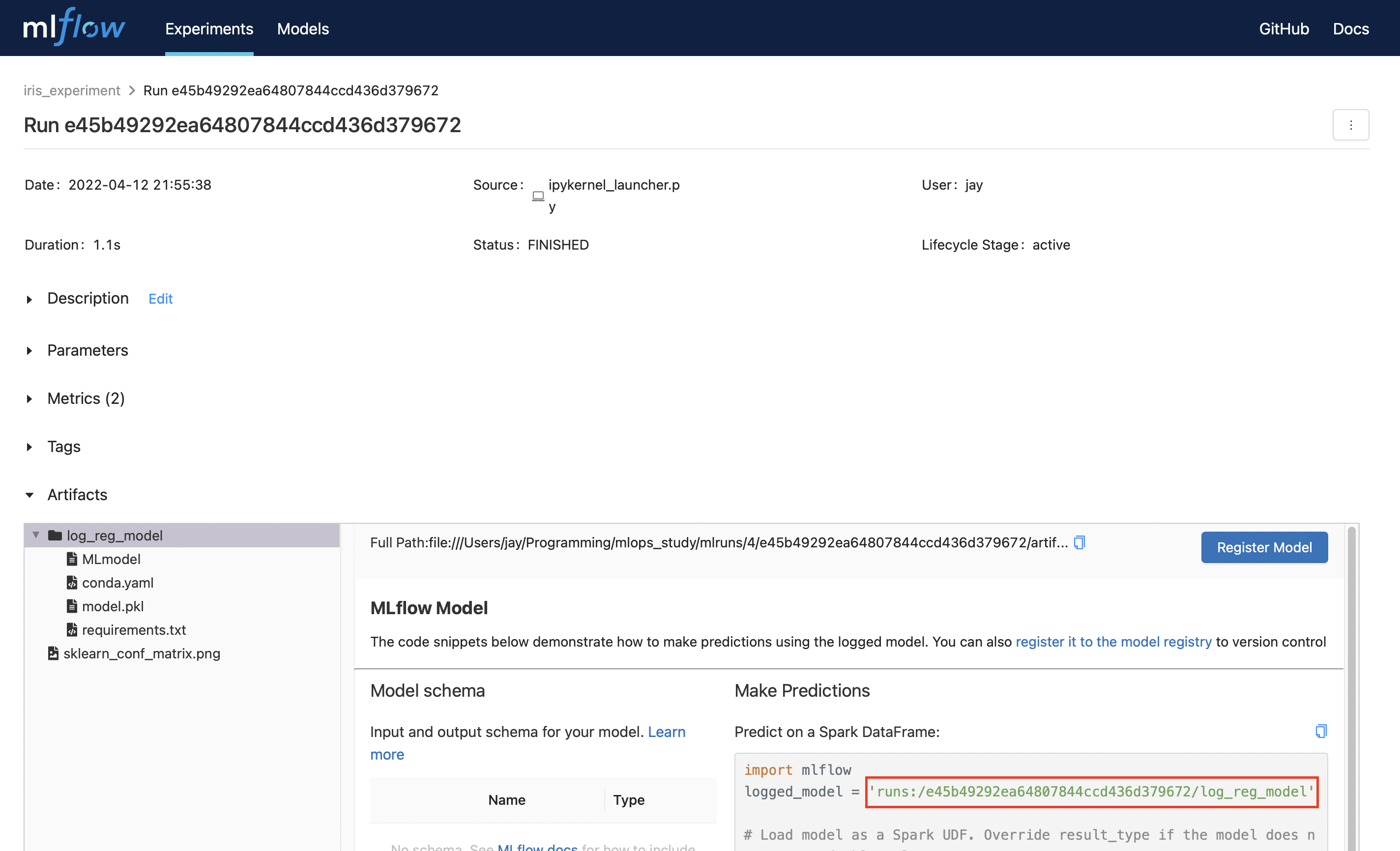
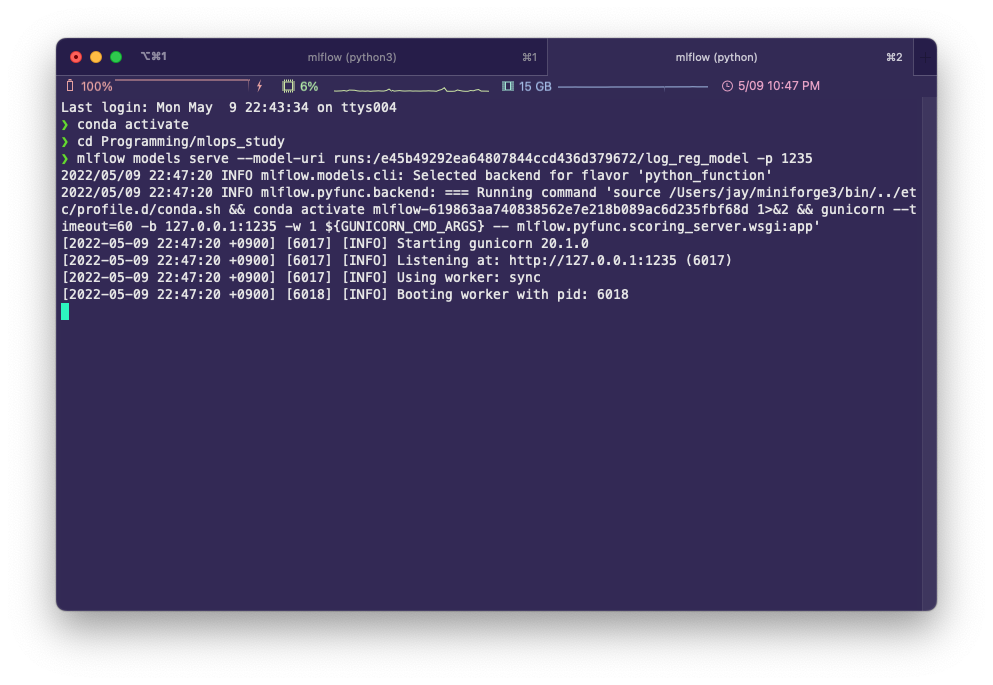
터미널에서 새 탭이나 새 창을 열고 Inference 서버를 실행하며 모델을 배포한다. 주소나 포트 번호는 ui 서버와 다르게 사용해야 한다.
(iterm 기준 command + t 로 새 탭 열기가 가능하다.)
mlflow models serve --model-uri runs:/e45b49292ea64807844ccd436d379672/log_reg_model -p 1235
POST request 쿼리를 사용한 inference
다음과 같이 쿼리문을 작성하고, subprocess에 쿼리문을 입력해 실행하면 다음과 같은 결과를 얻을 수 있다.
query = ["curl", "-X", "POST", "-H", "Content-Type:application/json; format=pandas-split", "--data", x_input, "http://127.0.0.1:1235/invocations"]
proc = subprocess.run(query, stdout=subprocess.PIPE, encoding='utf-8')
output = proc.stdout
preds = pd.DataFrame([json.loads(output)])
preds

이때 이 쿼리문의 각각의 명령어와 파라미터들은 다음과 같은 의미를 가진다.
curl: cli에서 데이터 전송을 위해 사용하는 라이브러리인 cURL의 명령어-X POST: REST API 메소드를 POST로 설정한다.-H Content-Type:application/json: 헤더의 컨텐츠 타입을 application/json으로 설정한다. {key:value}의 형태로 전송된다.format=pandas-split: json의 형식은 pandas-split으로 지정한다.--data {x_input}: 데이터엔 json 오브젝트가 입력된다.http://127.0.0.1:1235/invocations: POST request를 전달할 서버 주소
마지막으로 Inference 결과물이 제대로 예측됐는지 확인해본다.
val_acc = accuracy_score(y, preds.T)
eval_acc
>>>
0.9
conf_matrix = confusion_matrix(y, preds.T)
ax = sns.heatmap(conf_matrix, annot=True, fmt='g')
ax.invert_xaxis()
ax.invert_yaxis()
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title("Confusion Matrix")
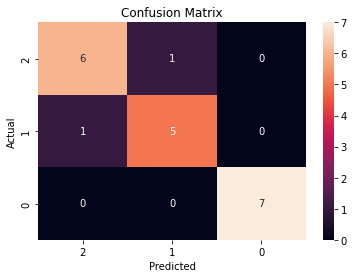
20개 중 총 18개의 데이터에 대해 예측에 성공했다.
출처
'mlops' 카테고리의 다른 글
더보기| (MLOps) MLFlow 기초 - 모델 배포 및 쿼리 | 2022. 05. 09 |
|---|---|
| (MLOps) MLFlow 기초 - 실행 및 로깅 | 2022. 04. 12 |