Tablesense 논문 리뷰 (TableSense - Spreadsheet Table Detection with Convolutional Neural Networks)

TableSense: Spreadsheet Table Detection with Convolutional Neural Networks 논문 데이터셋
Abstract & Problem Statement
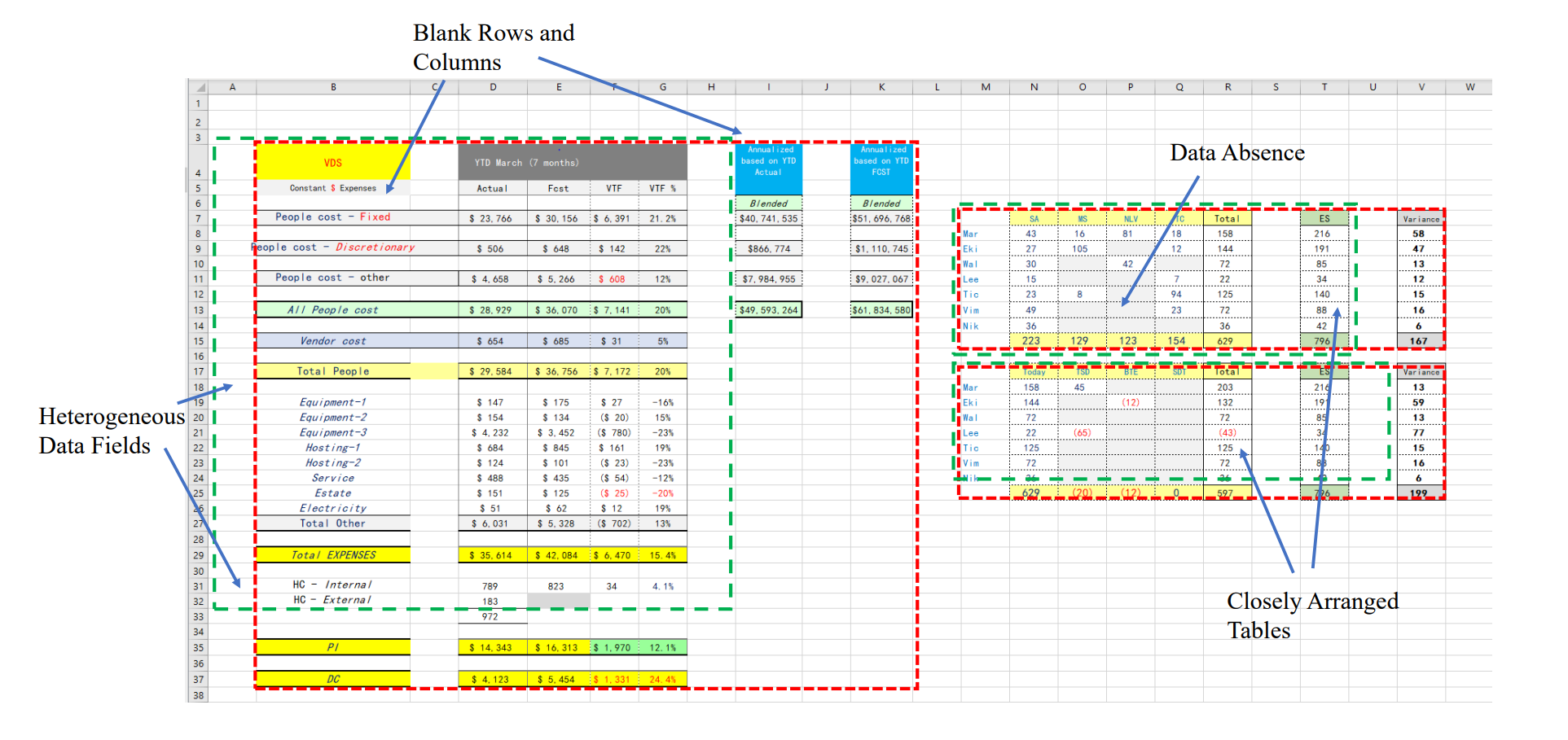
Spreadsheet table detection은 엑셀 파일 등에서 테이블이 존재하는 영역, 정확히는 top, left, bottom, right 네 방향의 boundary를 감지하는 종류의 과제를 말한다. 스프레드 시트라는 2차원 좌표계 내에서 bounding box를 추출하는 과제이므로 얼핏 보면 이미지 object detection과 비슷한 느낌이 있다. 실제로도 저자는 이 문제를 해결하기 위한 base algorithm으로 딥러닝 이미지 처리 분야에서 real-time object detection의 포문을 열었던 모델인 Faster R-CNN을 사용했다. 그러나 이 과제는 이미지의 object detection과 결정적인 차이점이 존재한다.
먼저, 이미지 object detection은 평가지표가 Intersection-over-Union(IoU)라는 것이다. Bounding box라는 것이 완전히 절대적인 기준에 의해 라벨링 된 것이 아닌(비록 일관성 있는 라벨링을 가능한 유지하려는 노력은 있었겠지만) 인간의 시각을 기준으로 임의로 부여된 것이다 보니, 아래 그림과 같이 예측 bounding box가 ground truth와 약간의 차이가 있더라도 IoU는 충분히 높게 측정되고, 인간의 눈으로 보기에도 정답이라고 인정할 수준이 된다.

하지만 엑셀 파일에서 테이블을 추출하는 작업은 가능한 한 셀의 오차도 없이 정확해야 한다. 이미지 처리에 비교하자면 1픽셀의 오차도 허용하면 안되는 상황인 것이다. 만약 테이블의 가장 우측 또는 최하단에 중요한 정보가 포함되어 있고, bounding box에서 이런 row나 column만 제외된다면 추출된 테이블 활용에 문제가 생길 것이다.
그리고 입력 데이터의 성격도 다르다. 이미지는 각 픽셀당 3채널에 R, G, B 색상 정보를 가지고 있는데, 엑셀에서 하나의 셀이 품고 있는 정보는 배경색, 선 스타일, 입력값, 수식 등등… 훨씬 많다. 게다가 가로 또는 세로가 편향적으로 길쭉한 이미지나 객체는 거의 없지만, 엑셀 파일에선 가로보다 세로 길이가 100배 이상 길쭉한 비율을 가진 테이블을 흔히 찾을 수 있다.
저자는 위 문제를 해결하기 위해 새로운 모델 구조와 평가방법, 학습 방법을 제시했고, 관련 데이터셋을 구축하는 성과를 올렸다. 비록 이 분야 자체가 사람들의 관심도가 높은 편은 아니지만, 논문은 엑셀의 본고장 마이크로소프트의 연구진들에 의해 작성됐고 연구진들의 후속 논문에서도 이 Tablesense 논문이 꾸준하게 사용되고 있기 때문에 한번쯤 볼만한 논문이다.
IoU vs EoB
이후부턴 bounding box를 편의상 bbox로 줄여 부르겠다. Object detection의 가장 보편적인 평가지표는 Intersection-over-Union이다. 이는 예측 bbox $(B)$와 실제 bbox $(B’)$의 일치도를 나타내는데, 두 bbox간의 교집합 넓이를 합집합 넓이로 나눈 것이다.
이는 bbox의 절대적인 크기와 상관 없이 각 bbox간 오차의 상대적 비율만 고려한다. 따라서 큰 bbox간 IoU를 구할 수록 작은 절대 오차는 무시된다. 같은 크기지만 해상도가 다른 20pixel x 20pixel 이미지와 1000pixel x 1000pixel 이미지가 있을 때, 20 x 20 해상도 이미지에선 한쪽 boundary가 5픽셀 차이가 나면 인간의 시각 기준으로 매우 큰 차이로 느껴지고 실제로 IoU도 작게 측정겠지만, 1000 x 1000 해상도 이미지에선 한쪽 boundary가 5픽셀 차이나도 인간의 시각은 문제 없이 bbox를 정답으로 인식하고 IoU역시 높게 측정된다. 따라서 전체 영역이 커질수록 작은 차이가 무시되는 IoU는 엑셀 테이블 추출의 평가지표로 사용하기에 매우 부적합하기에 저자들은 새로운 평가지표인 Error-of-Boundary를 제시한다.
EoB는 예측과 정답 boundary의 최대 절대 오차가 기준이다. 예를 들어, 상/하/좌/우 boundary의 예측값과 정답이 각각 2/0/1/1 셀 만큼씩 차이가 난다면, top-boundary의 오차가 2로 가장 크고, 따라서 EoB는 이 경우 2가 된다. 덕분에 테이블이 크기와 상관 없이 영역이 아닌 boundary를 기준으로 평가할 수 있다.
Datasets & Framework
스프레드 시트 파일을 웹에서 크롤링해 그 중 10220개의 시트에 라벨링을 해 훈련 셋으로 사용하고 이와 겹치지 않는 400개의 시트를 테스트 셋으로 사용했다.
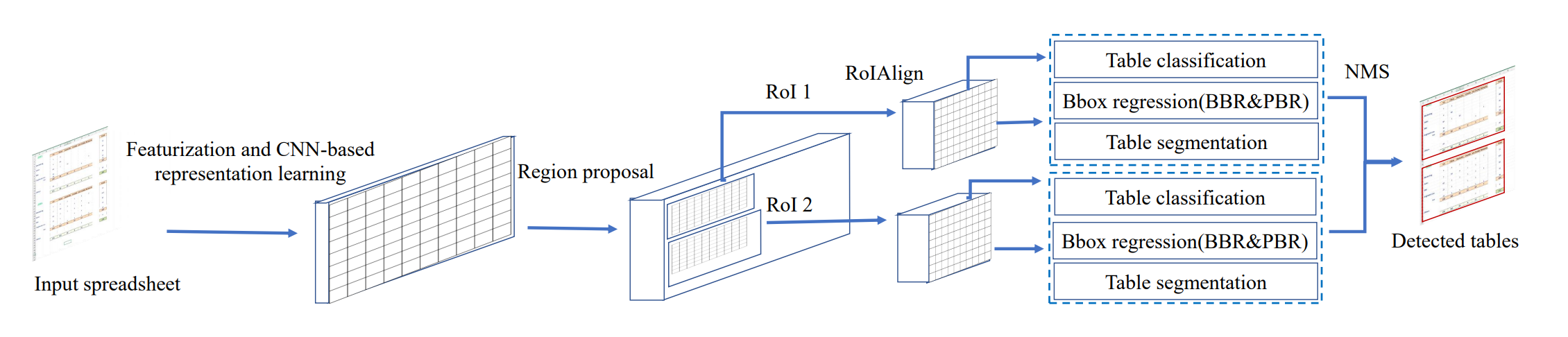
Tablesense는 다음 다섯 단계에 걸쳐 테이블을 추출한다.
- Cell Featurization
- CNN Backbone
- Region Proposal Network
- Bounding Box Regresssion
- Precise Bounding Box Regression
Cell Featurization은 시트를 텐서로 변환하는 단계이다. 이미지 파일은 한 픽셀에 색상 3채널의 정보를 담고 있지만, 엑셀 파일은 한 셀당 20채널로 나타낸다. 각 채널마다 영문자 비율, 숫자 비율, 입력값 길이, 선 스타일 적용 유무, 배경색, 글자색, 수식 적용 여부 등등의 정보를 담게 된다.
이후 CNN backbone, Region Proposal Network, Bounding Box Regression은 Faster R-CNN의 알고리즘을 그대로 사용한다. 약간의 차이점이 있다면 resnet backbone에서 pooling layer를 제거한것과, RPN의 anchor세트가 base size 8 ~ 4096, ratio 1/256 ~ 256 까지 존재하는 등 다양한 크기와 극단적으로 편향된 비율을 가진 케이스까지 포함한다는 점이다.
주목해야 할 부분은 이 모델의 핵심 구조인 PBR(Precise Bounding Box Regression) 모듈이다. BBR모듈의 Regrion of Interest를 기반으로 세부적인 boundary를 보정하는데, 어떤 원리인지 자세히 알아보자.
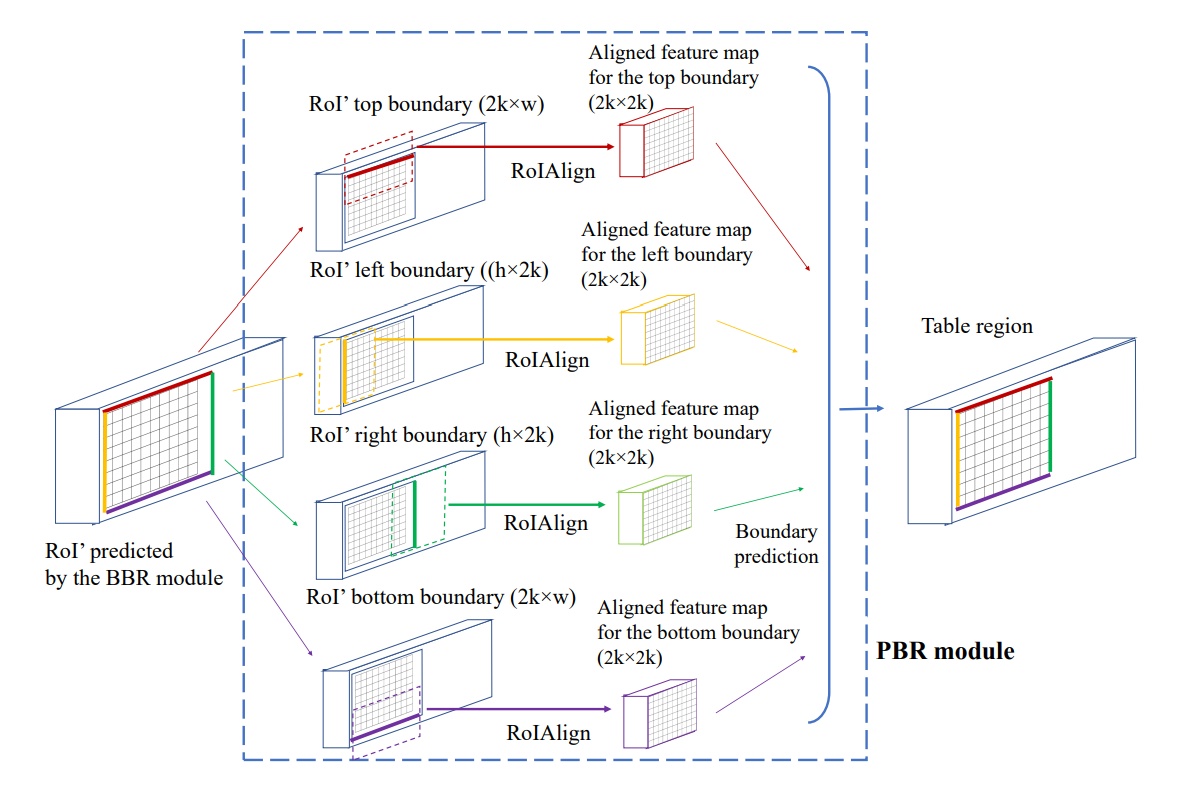
BBR 모듈로 출력된 RoI는 부정확한 boundary를 가지고 있기 때문에, 이 boundary를 기준으로 receptive field를 새로 설정해 예측값과 정답값의 차이를 구하게 된다. 좌, 우 boundary에 대해서는 수평방향으로 $2k$, 상/하 boundary에 대해서는 수직방향으로 $2k$의 사이즈를 가지는 좁은 receptive 필드는 예측 boundary와 실제 boundary의 오차를 최소화하는데 적합하다. 논문에선 적절한 $k$를 7로 설정했다. $k$가 너무 크면 여러개의 작은 표가 가까이 붙어있는 경우 정답을 예측하는데 방해가 되고, 너무 작으면 receptive field가 ground truth boundary를 포함하지 못할 확률이 높아지기 때문이다. 네 방향의 receptive field로부터 추출된 feature map은 RoIAlign을 통해 $2k \times 2k$ 크기의 텐서로 고정되고, regression 이후 세부적인 보정값을 출력하게 된다. Receptive field의 폭 또는 높이와 RoIAlign 후의 폭 또는 높이가 같기 때문에 정보의 손실이 거의 없게 된다. PBR모듈의 출력값을 통해 BBR모듈이 출력한 RoI를 보정하게 되면 경계 오차가 매우 적은 bbox를 얻을 수 있다.
Target & Loss Function
기존 Faster R-CNN의 손실함수는 다음과 같이 smooth L1을 사용한다.
타겟은 다음과 같이 설정된다.
$x, w$는 각각 bbox의 중심 $x$좌표와 폭을 나타내고, $y, h$에 대해서도 동일한 식을 사용한다. 첨자가 없는 문자는 예측 bbox의 값, 아래첨자 $a$가 붙은 문자는 anchor box의 값, 윗첨자 $*$가 붙은 문자는 ground-truth box의 값을 나타낸다. 이 식에서 $x$에 대한 손실함수의 기울기는 $w_a$에 대해 반비례하고, $w$에 대한 손실함수의 기울기는 $w$에 대해 반비례한다. 즉 anchor box가 클 수록 중심 좌표에 대한 가중치 업데이트 값이 작아지고, 마찬가지로 예측 bbox가 클 수록 폭과 높이에 대한 가중치 업데이트 값이 작아진다. 이는 bbox의 크기와 상관 없이 안정적인 훈련을 보장하지만 boundary를 정확하게 예측하는 데에는 적합하지 않다.
따라서 PBR 모듈은 새로운 손실함수와 타겟을 사용한다.
$t_i - t_i^*$를 계산해 보면 anchor box에 관련된 변수들은 사라지고 예측값과 ground-truth의 절댓값 차이만이 남는다. 따라서 PBR 모듈의 가중치 업데이트는 절대 오차에 따라 이뤄진다. 또한 함수 $R$에서 오차가 $k$ 이상일 때는 기울기가 $0.5k^2$으로 고정되기에 예측값과 ground-truth간의 차이가 너무 크더라도 업데이트가 급격하게 이루어지는 상황을 방지했다.
모든 손실함수는 역전파 전에 더해진다. 기본적으로 PBR 모듈만으론 Region Proposal Network의 안정적인 훈련을 기대할 수 없기 때문에 BBR모듈의 smooth L1 함수도 버려지지 않고 여전히 사용된다.
Evaluation Results
다음과 같은 baseline 모델들과의 비교를 진행했다.
- Region-growth : 특정 셀부터 8방향으로 접한 모든 셀로 영역을 가능한 확장시키고 확장이 끝났을 때의 영역을 테이블로 추출한다.
- Region-growth + SVM : Regtion-growth 방식으로 추출한 테이블이 실제 테이블인지 아닌지 예측하는 classifier를 학습시킨다.
- Mask R-CNN : 당시에 sota를 달성한 object detection 모델이다.
- YOLO-v3 : 당시에 sota를 달성한 real time object detection 모델이다.
- Faster R-CNN : 당시에 sota를 달성한 real time object detection 모델이고 TableSense의 base 알고리즘이다. YOLO보단 느린 대신 정확도는 조금 더 높다.
측정은 EoB-0와 EoB-2를 기준으로 했다. EoB-0는 EoB가 0인 경우만 예측 성공으로 인정하는 것이고, EoB-2는 2이하 까지 예측 성공으로 인정하는 것이다. 결과는 논문에 나와 있듯이 TableSense가 다른 baseline에 비해 압도적으로 높은 recall/precision을 기록했다.
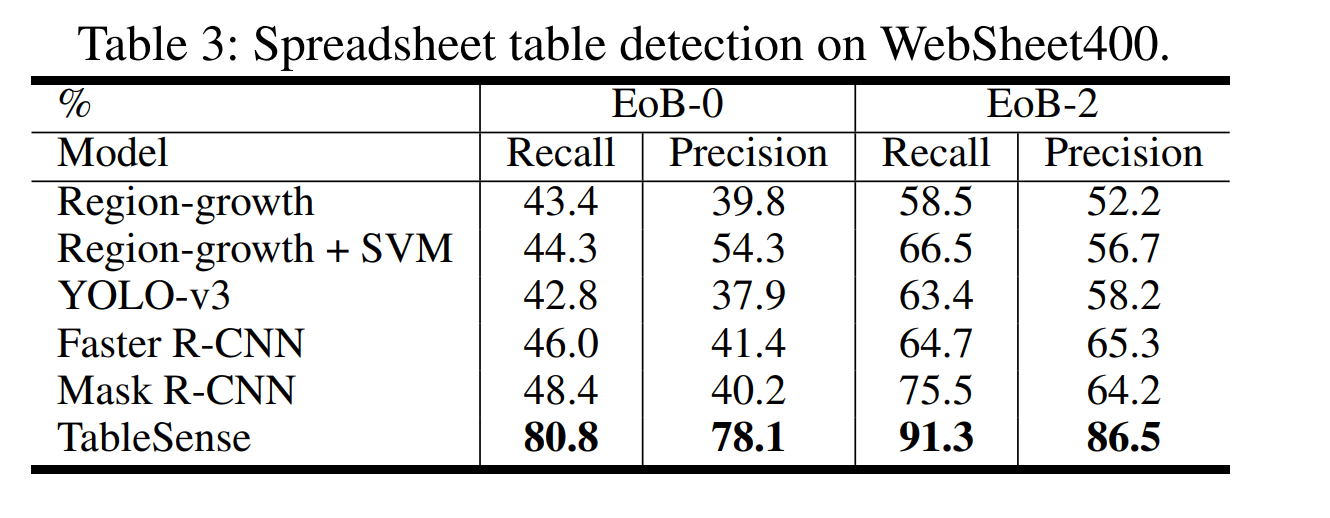
또한 cell featurization 과정에서 특정 feature를 제외시켰을 때보다 모든 feature를 전부 사용했을때 성능이 가장 좋았다고 한다.
모델이 훈련 중 스스로 불확실한 데이터에 대해서만 사람에게 라벨링을 요구하고 특정 조건을 만족하는 데이터는 스스로 라벨링 하도록 하는 Active Learning은 훈련 횟수가 증가함에 따라 오류가 점차 줄어드는 경향을 보임으로 제시한 학습법의 효율성을 입증했다고 한다.
'computer_vision' 카테고리의 다른 글
더보기| Tablesense 논문 리뷰 (TableSense - Spreadsheet Table Detection with Convolutional Neural Networks) | 2021. 12. 10 |
|---|